通过前面两篇文章的介绍,我们大概已经知道了 Elasticsearch处理数据的流程,其中在Elasticsearch和磁盘之间还有一层称为FileSystem Cache的系统缓存,正是由于这层cache的存在才使得es能够拥有更快搜索响应能力。
我们都知道一个index是由若干个segment组成,随着每个segment的不断增长,我们索引一条数据后可能要经过分钟级别的延迟才能被搜索,为什么有种这么大的延迟,这里面的瓶颈点主要在磁盘。
持久化一个segment需要fsync操作用来确保segment能够物理的被写入磁盘以真正的避免数据丢失,但是fsync操作比较耗时,所以它不能在每索引一条数据后就执行一次,如果那样索引和搜索的延迟都会非常之大。
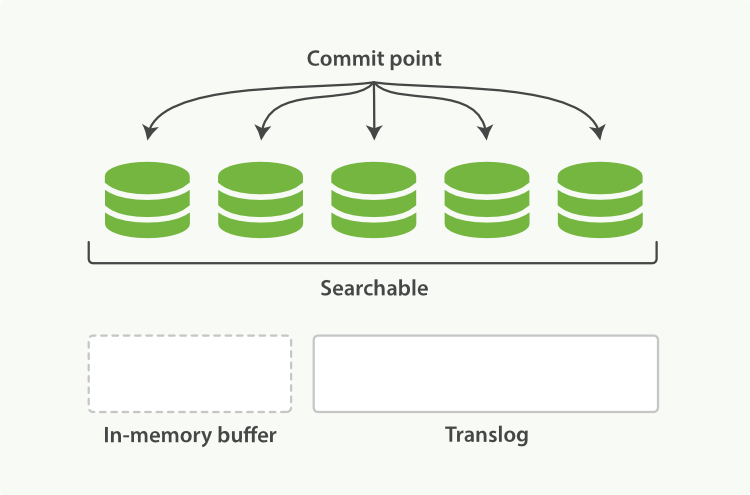
所以这里需要一个更轻量级的处理方式,从而保证搜索的延迟更小。这就需要用到上面提到的FileSystem Cache,所以在es中新增的document会被收集到indexing buffer区后被重写成一个segment然后直接写入filesystem cache中,这个操作是非常轻量级的,相对耗时较少,之后经过一定的间隔或外部触发后才会被flush到磁盘上,这个操作非常耗时。但只要sengment文件被写入cache后,这个sengment就可以打开和查询,从而确保在短时间内就可以搜到,而不用执行一个full commit也就是fsync操作,这是一个非常轻量级的处理方式而且是可以高频次的被执行,而不会破坏es的性能。
如下图:
在elasticsearch里面,这个轻量级的写入和打开一个cache中的segment的操作叫做refresh,默认情况下,es集群中的每个shard会每隔1秒自动refresh一次,这就是我们为什么说es是近实时的搜索引擎而不是实时的,也就是说给索引插入一条数据后,我们需要等待1秒才能被搜到这条数据,这是es对写入和查询一个平衡的设置方式,这样设置既提升了es的索引写入效率同时也使得es能够近实时检索数据。
refresh的用法如下:
POST /_refresh //刷新所有的索引
POST /blogs/_refresh //刷新指定的索引refresh操作相比commit操作是非常轻量级的但是它仍然会耗费一定的性能,所以不建议在每插入一条数据后就执行一次refresh命令,es默认的1秒的延迟对于大多数场景基本都可以接受。
当然并不是所有的业务场景都需要每秒都refresh一次,如果你短时间内要索引大量的数据,为了优化索引的写入速度,我们可以设置更大的refresh间隔,从而提升写入性能,命令如下:
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}上面的参数是可以随时动态的设置到一个存在的索引里面,如果我们正在插入超大索引时,我们完全可以先关闭掉这个refresh机制,等写入完毕之后再重新打开,这样以来就能大大提升写入速度。
命令如下:
PUT /my_logs/_settings
{ "refresh_interval": -1 } //禁用刷新机制
PUT /my_logs/_settings
{ "refresh_interval": "1s" } //设置每秒刷新一次注意refresh_interval的参数是可以带时间周期的,如果你只写了个1,那就代表每隔1毫秒刷新一次索引,所以设置这个参数时务必要谨慎。