文章目录
- 前言
- 一、es kibana ik 安装
- 二、使用步骤
- 访问地址
- api调用
- 总结
前言
全文索引,首选es,最近看了下easy-es,完全与mybatis-plus类似,简单试了下,很不错;
easy-es 使用的 7.14.0,这里也仅用此版本说明;
安装了桌面版本docker desktop
安装了es 和 kibana 中文分词 ik 都是 7.14.0
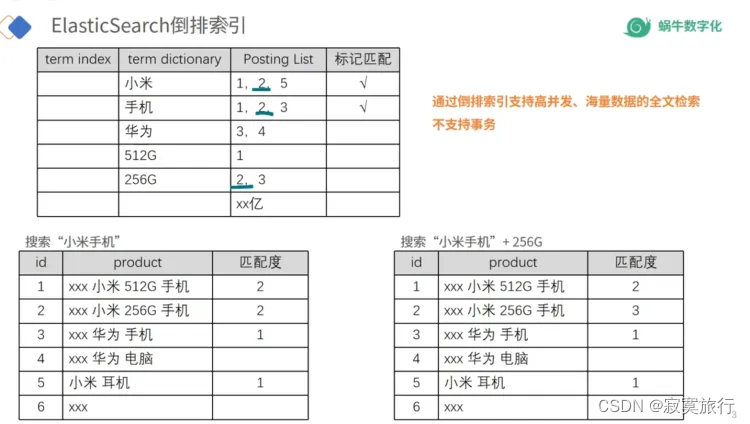
倒排索引
- 正排索引: 索引>>数据(mysql)
- 文档中的关键词所在文档id列表;所有的这些信息就是倒排文件(还记录了关键词所在位置,出现次数)
一、es kibana ik 安装
# 创建network
docker network create elastic
# 启动es
docker run --name elastic -p 9200:9200 -p 9300:9300 --network=elastic -e "discovery.type=single-node" -d elasticsearch:7.14.0
# 启动kibana
docker run -d --name kibana --network=elastic -p 5601:5601 kibana:7.14.0
# 进入容器
docker exec -it elastic /bin/bash
# 执行安装命令
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
# 修改elastic 配置文件 vi config/elasticsearch.yml 设置用户名 密码添加
xpack.security.enabled: true
# 执行命令 生产
./bin/elasticsearch-setup-passwords auto
# 日志会有如下内容(es 用户名密码):
Changed password for user apm_system
PASSWORD apm_system = XeKm1qyZYOEWNhToX27q
Changed password for user kibana_system
PASSWORD kibana_system = 8XOWmnjzdttz0ELilk8T
Changed password for user kibana
PASSWORD kibana = 8XOWmnjzdttz0ELilk8T
Changed password for user logstash_system
PASSWORD logstash_system = 1Bxkb28EPpCzsnkeHkDu
Changed password for user beats_system
PASSWORD beats_system = ZWvas9mn6gnrYRdNhaoM
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = M0ApshjIWQZ5QQ0yN7Hy
Changed password for user elastic
PASSWORD elastic = NUZvcsKDRdvJwrpV1i1J
# 进入kibana 容器 设置kibana (es:地址 用户名 密码)配置文件 vi config/kibana.yml
elasticsearch.hosts: [ "http://elastic:9200" ]
elasticsearch.username: "elastic"
elasticsearch.password: "NUZvcsKDRdvJwrpV1i1J"
# 这里的用户名密码,在上面随机选一个就行,我这个选的是最后一个
重启两个服务
注意: 修改自定义密码,需要重新配置kibana中的用户名密码
二、使用步骤
访问地址
es : localhost:9200
kibana : localhost:5601
api调用
es 基本增删改查
- text 会进行分词
- keyword 不会分词
- term 精准查询
- terms 批量精准查询
- 排序sort
- 分页 from size
- 高亮查询 highlight
- 聚合函数 分组查询 aggs
# 获取所有movies
GET /movies/_search
{
"query": {
"match_all": {}
}
}
# 验证分词
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["我爱中国"]
}
# 获取所有索引
GET _cat/indices
# 删除索引
DELETE movies
# 创建索引 配置映射
PUT /movies
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "double"
},
"no":{
"type": "keyword"
}
}
}
}
GET movies
# test 测试
GET test
# 有则修改,无则增加
PUT test/doc/2
{
"name":"wangfei",
"age":27,
"desc":"热天还不让后人不认同"
}
PUT test/doc/1
{
"name":"wangjifei",
"age":27,
"desc":"萨芬我反胃为范围额"
}
PUT test/doc/3
{
"name":"wangyang",
"age":30,
"desc":"点在我心内的几首歌"
}
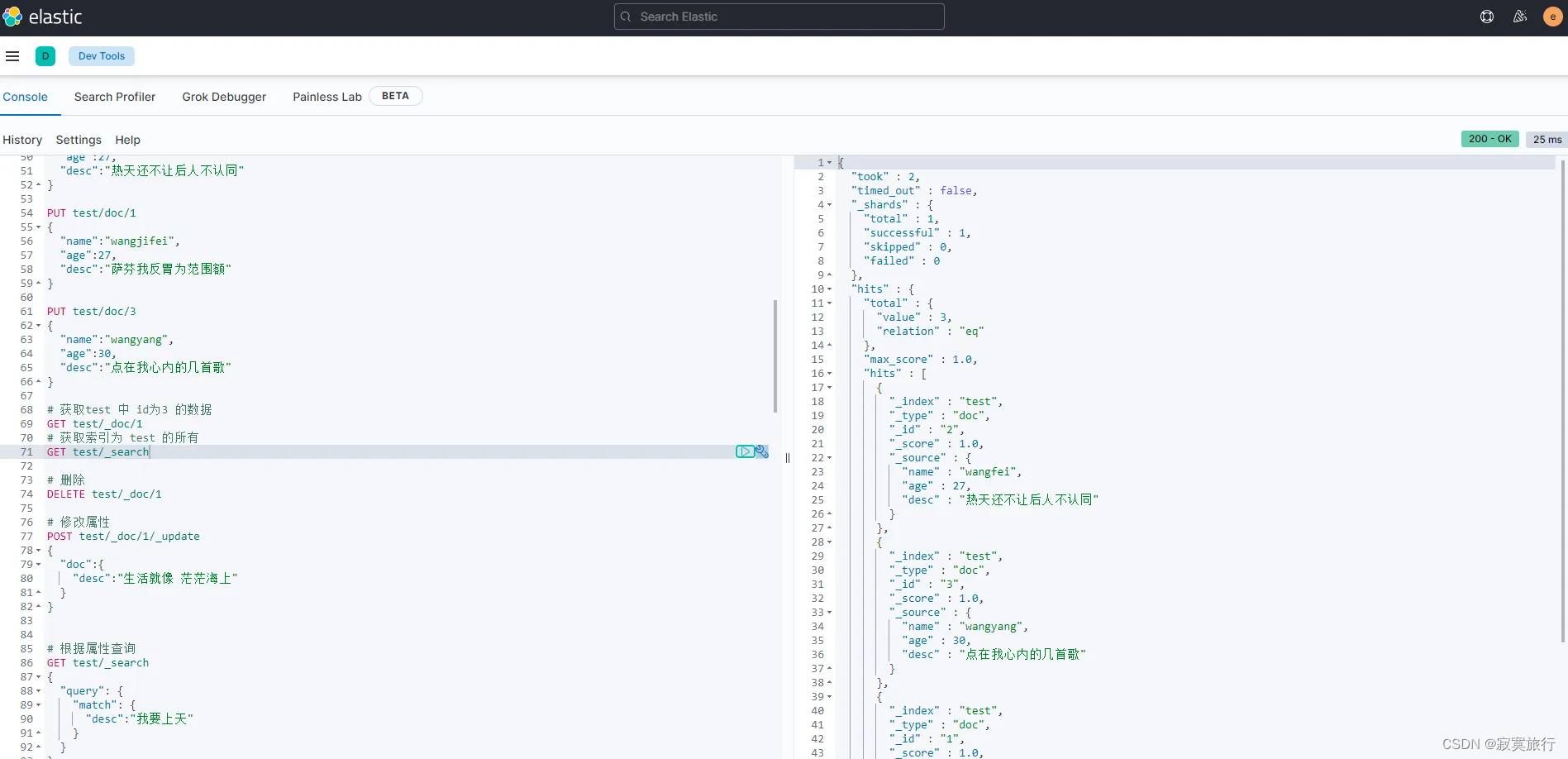
# 获取test 中 id为3 的数据
GET test/_doc/1
# 获取索引为 test 的所有
GET test/_search
# 删除
DELETE test/_doc/1
# 修改属性
POST test/_doc/1/_update
{
"doc":{
"desc":"生活就像 茫茫海上"
}
}
# 根据属性查询
GET test/_search
{
"query": {
"match": {
"desc":"我要上天"
}
}
}
# 间隔搜索 slop 代表间隔多少个字符内
GET test/_search
{
"query": {
"match_phrase": {
"desc":{
"query": "生活海上",
"slop": 6
}
}
}
}
# 前缀匹配 highlight 高亮查询
GET /test/_search
{
"query": {
"match_phrase_prefix": {
"desc": "像"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"desc": {}
}
}
}
# 多字段查询
GET test/_search
{
"query": {
"multi_match": {
"query": "生活海上",
"fields": ["name","desc"]
}
}
}
# 排序查询
GET test/_search
{
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
# bool: must 同时满足/should 满足一个即可
GET test/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"age": 27
}
},
{
"match": {
"desc": "上"
}
}
]
}
}
}
GET test/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"age": 27
}
},
{
"match": {
"desc": "的"
}
}
]
}
}
}
# 过滤
GET test/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"age": {
"gte": 28,
"lte": 30
}
}
}
]
}
},
"_source": ["name"]
}
# 排序 分页查询
GET test/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 1,
"size": 2
}
# 高亮查询 highlight
GET /test/_search
{
"query": {
"match": {
"desc": "后人"
}
},
"highlight": {
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"desc": {}
}
}
}
# trem 精准查询
GET test/_search
{
"query": {
"term": {
"age": {
"value": "30"
}
}
}
}
# trems 精准查询多个
GET test/_search
{
"query": {
"terms": {
"age": [
27,
30
]
}
}
}
# 聚合函数
GET test/_search
{
"query": {
"match_all": {}
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
}
}
# 分组查询 再函数平均值
GET test/_search
{
"query": {
"match_all": {}
},
"aggs": {
"mygroup":{
"range": {
"field": "age",
"ranges": [
{
"from": 10,
"to": 29
},
{
"from": 29,
"to": 30
}
]
},
"aggs": {
"my_avg": {
"avg": {
"field": "age"
}
}
}
}
}
}
总结
easy-es使用起来真的是很丝滑,可以直接看官网介绍了,文档很全;
/**
* LambdaEsIndexWrapper构造器使测案例一:创建索引,通过开箱即用的方法创建
*/
@Test
public void testCreateIndex() {
LambdaEsIndexWrapper<Document> wrapper = new LambdaEsIndexWrapper<>();
// 此处简单起见 索引名称须保持和实体类名称一致,字母小写 后面章节会教大家更如何灵活配置和使用索引
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
// 此处将文章标题映射为keyword类型(不支持分词),文档内容映射为text类型(支持分词查询)
wrapper.mapping(Document::getTitle, FieldType.KEYWORD, 2.0f)
.mapping(Document::getLocation, FieldType.GEO_POINT)
.mapping(Document::getGeoLocation, FieldType.GEO_SHAPE)
.mapping(Document::getContent, FieldType.TEXT, Analyzer.IK_SMART, Analyzer.IK_MAX_WORD);
// 设置分片及副本信息,可缺省
wrapper.settings(3, 2);
// 设置别名信息,可缺省
String aliasName = "daily";
wrapper.createAlias(aliasName);
// 设置父子信息,若无父子文档关系则无需设置
wrapper.join("joinField", "document", "comment");
// 创建索引
boolean isOk = documentMapper.createIndex(wrapper);
Assertions.assertTrue(isOk);
}
/**
* LambdaEsIndexWrapper构造器使测案例二:创建索引,通过自定义map 最难用但也最灵活
*/
@Test
public void testCreateIndexByMap() {
// 演示通过自定义map创建索引,最为灵活,若方案一不能满足时可用此方法
LambdaEsIndexWrapper<Document> wrapper = new LambdaEsIndexWrapper<>();
wrapper.indexName(Document.class.getSimpleName().toLowerCase());
wrapper.settings(3, 2);
Map<String, Object> map = new HashMap<>();
Map<String, Object> prop = new HashMap<>();
Map<String, String> field = new HashMap<>();
field.put("type", FieldType.KEYWORD.getType());
prop.put("this_is_field", field);
map.put("properties", prop);
wrapper.mapping(map);
boolean isOk = documentMapper.createIndex(wrapper);
Assertions.assertTrue(isOk);
}
/**
* LambdaEsIndexWrapper构造器使测案例三:更新索引(不推荐使用,因为索引变动ES会重建索引,有其它更好的方式,可参考后面索引托管章节)
*/
@Test
public void testUpdateIndex() {
// 测试更新索引
LambdaEsIndexWrapper<Document> wrapper = new LambdaEsIndexWrapper<>();
// 指定要更新哪个索引
String indexName = Document.class.getSimpleName().toLowerCase();
wrapper.indexName(indexName);
wrapper.mapping(Document::getCreator, FieldType.KEYWORD);
wrapper.mapping(Document::getGmtCreate, FieldType.DATE);
boolean isOk = documentMapper.updateIndex(wrapper);
Assertions.assertTrue(isOk);
}



![标题:C++初阶 | [十] stack 和 queue](https://img-blog.csdnimg.cn/direct/d2f114767d5f4c44b261d56f4e32f3dd.png)


