前言
类型及映射是Elasticsearch中重要的两个概念。本章节袁老师将带领同学们来学习Elasticsearch中的类型和映射部分的内容。先透露一下,在Elasticsearch中,类型(type)相当于关系数据库中的table概念;映射(mapping)相当于数据库中的schema,用来约束字段的类型。有些小伙伴此时可能会感到云里雾里,那我们就带着疑问继续去探讨相关的内容。

一. 创建字段映射
1.字段映射介绍
有了索引库 ,等于有了数据库中的Database。接下来就需要索引库中的类型了,也就是数据库中的表。创建数据库表需要设置字段约束,索引库也一样,在创建索引库的类型时,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫作字段映射(Mapping)。
注意:Elasticsearch7.x取消了索引type类型的设置,不允许指定类型,默认为_doc,但字段仍然是有的,我们需要设置字段的约束信息,叫作字段映射(Mapping)。
字段的约束我们在学习Lucene中我们都见到过,包括到不限于:
- 字段的数据类型
- 是否要存储
- 是否要索引
- 是否分词
- 分词器是什么
我们一起来看下创建的语法。
2.创建字段映射语法
2.1 创建字段映射语法
语法格式:请求方式依然是PUT。
javascript">PUT /索引库名/_mapping/typeName
{
"properties": {
"字段名": {
"type": "类型",
"index": true,
"store": false,
"analyzer": "分词器"
}
}
}类型名称:就是前面讲的type的概念,类似于数据库中的表。
字段名:字段名称由开发者自定义,每个字段名下可指定多个属性。具体属性见下表:
| 属性 | 描述 |
| type | 类型,可以是text、keyword、long、short、date、integer、object等 |
| index | 是否索引,默认为true |
| store | 是否存储,默认为false |
| analyzer | 分词器,例如设置为ik_max_word值,即使用IK分词器 |
2.2 创建字段映射案例
演示示例:
javascript">PUT /yx/_mapping/goods
{
"properties": {
"title": {
"type": "text",
"store": true,
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": false,
"store": true
},
"price": {
"type": "float"
}
}
}如果yx索引库存在,响应结果见下:
javascript">{
"acknowledged": true
}如果yx索引库不存在,响应结果见下:
javascript">{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index",
"resource.type": "index_or_alias",
"resource.id": "yx",
"index_uuid": "_na_",
"index": "yx"
}
],
"type": "index_not_found_exception",
"reason": "no such index",
"resource.type": "index_or_alias",
"resource.id": "yx",
"index_uuid": "_na_",
"index": "yx"
},
"status": 404
}注意:在进行创建索引库中的字段映射时,需要先确保索引库被创建,否则会抛index_not_found_exception异常。
上述案例中,就给“yx”这个索引库添加了一个名为goods的类型,并且在类型中设置了3个字段:
- title:商品标题
- images:商品图片
- price:商品价格
并且给这些字段设置了一些属性,至于这些属性对应的含义,我们在后续会详细介绍。
二. 查看映射关系
语法格式:
javascript">GET /索引库名/_mapping查看某个索引库中的所有类型的映射。如果要查看某个类型映射,可以在路径后面跟上类型名称。即:
javascript">GET /索引库名/_mapping/类型名演示示例:
javascript">GET /yx/_mapping
GET /yx/_mapping/goods响应结果:
javascript">{
"yx": {
"mappings": {
"goods": {
"properties": {
"images": {
"type": "keyword",
"index": false,
"store": true
},
"price": {
"type": "float"
},
"title": {
"type": "text",
"store": true,
"analyzer": "ik_max_word"
}
}
}
}
}
}三. 字段数据类型详解
Elasticsearch中支持的数据类型非常丰富。具体查看Field data types | Elasticsearch Guide [8.12] | Elastic文档介绍。
1.字段数据类型介绍
每个字段都有一个字段数据类型或字段类型。此类型指示字段包含的数据类型(如字符串或布尔值)及其预期用途。例如,可以将字符串索引到text字段和keyword字段。但是,text字段值将被分析用于全文搜索,而keyword字符串则保留原样用于过滤和排序。
字段类型按族分组。同一族中的类型具有完全相同的搜索行为,但可能具有不同的空间使用或性能特征。
目前,有两个类型族,keyword和text。其他类型族只有一个字段类型。例如,boolean类型族由一种字段类型组成:boolean。
2.字段数据类型分类
2.1 常用类型
Elasticsearch支持丰富的数据类型,见下表:
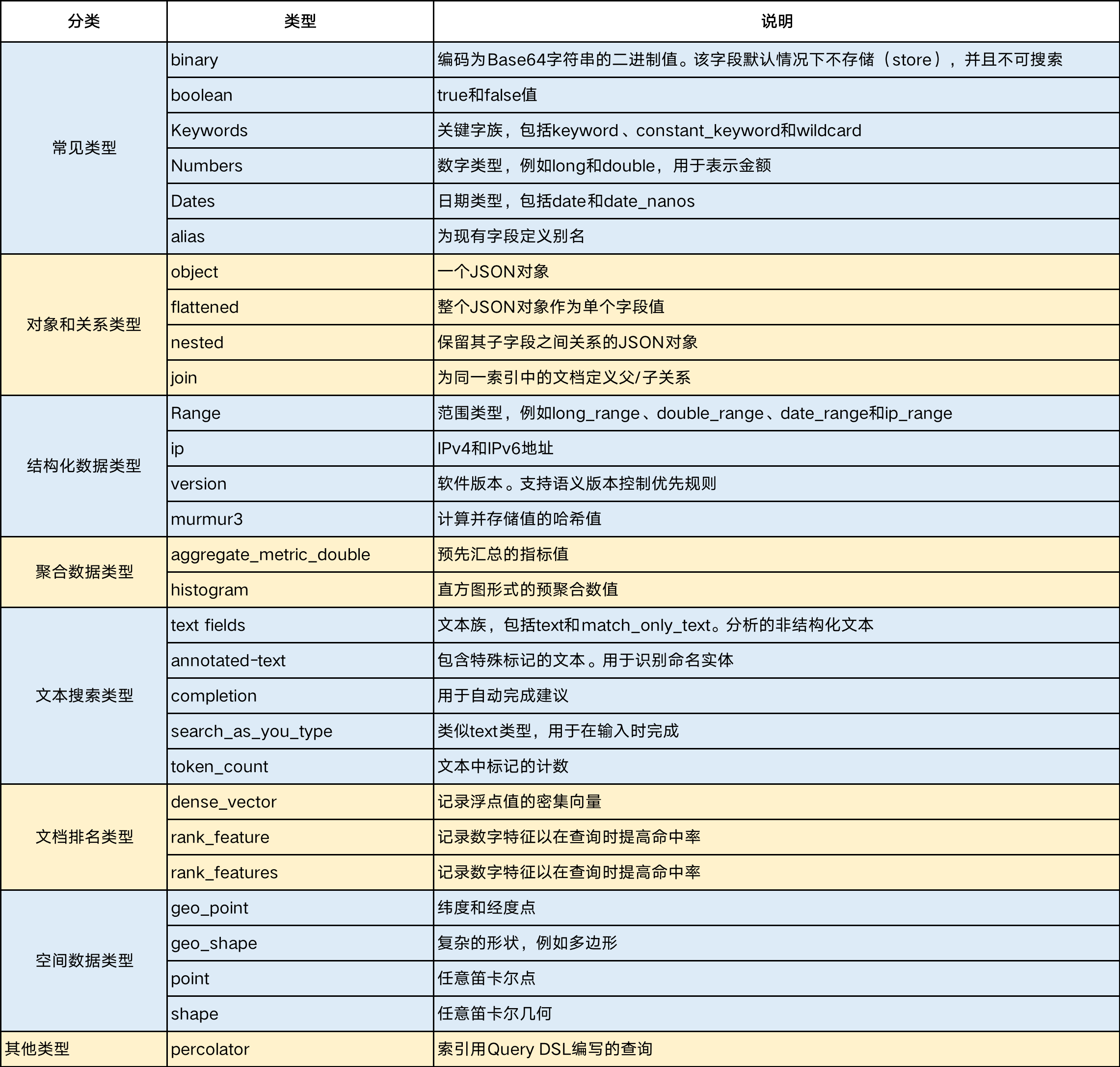
2.2 string类型
string类型取值见下:
- text:使用文本数据类型的字段,它们会被分词,文本字段不用于排序,很少用于聚合,如文章标题、正文。
- keyword:关键字数据类型,用于索引结构化内容的字段,不会被分词,必须完整匹配的内容,如邮箱、身份证号等。支持聚合。
这两种类型都是比较常用的,但有的时候,对于一个字符串字段,我们可能希望他两种都支持,此时,可以利用其多字段特性。
javascript">"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"sort":{
"type": "keyword"
}
},
"index": true
}
}2.3 Numerical数值类型
数值类型介绍见下:
- 基本数据类型:long、interger、short、byte、double、float、half_float
- float单精度32位
- double双精度64位
- half_float半精度16位
- 浮点数的高精度类型scaled_float
带有缩放因子的缩放类型浮点数,依靠一个 long数字类型通过一个固定的(double类型)缩放因数进行缩放。
需要指定一个精度因子,比如10或100。Elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
2.4 Date日期类型
Elasticsearch可以将日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
2.5 Array数组类型
进行匹配时,任意一个元素满足,都认为满足。
排序时,如果升序则用数组中的最小值来排序,如果降序则用数组中的最大值来排序。
javascript">字符串数组:["one", "two"]
整数数组:[1, 2]
数组的数组:[1, [2, 3]]等价于[1, 2, 3]
对象数组:[{"name": "Mary", "age": 12}, {"name": "John", "age": 10}]2.6 Object对象
JSON文档本质上是分层的。文档包含内部对象,内部对象本身还包含内部对象。
javascript">{
"region": "US",
"manager.name": "John Smith",
"manager.age": 30
}可以将上述的文档可以改写成以下形式。
javascript">{
"mappings": {
"properties": {
"region": {
"type": "keyword"
},
"manager": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}
}
}2.7 ip地址
IPv4和IPv6地址。
创建一个my_ip_addr索引库,并指定ip_addr字段的类型是ip。
javascript">PUT /my_ip_addr
{
"mappings": {
"_doc": {
"properties": {
"ip_addr": {
"type": "ip"
}
}
}
}
}
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my_ip_addr"
}向索引库中添加一条数据。
javascript">PUT /my_ip_addr/_doc/1
{
"ip_addr": "192.168.1.1"
}
{
"_index": "my_ip_addr",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}查询my_ip_addr索引库中的数据。
javascript">GET /my_ip_addr/_search
{
"query": {
"term": {
"ip_addr": "192.168.0.0/16"
}
}
}
{
"took": 52,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "my_ip_addr",
"_type": "_doc",
"_id": "1",
"_score": 1,
"_source": {
"ip_addr": "192.168.1.1"
}
}
]
}
}2.8 数组
在Elasticsearch中,数组不需要专用的字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值必须是相同的字段类型。
2.9 多领域
出于不同的目的,以不同的方式索引同一字段通常很有用。例如,一个string字段可以映射为一个text用于全文搜索的字段,也可以映射为一个keyword用于排序或聚合的字段。或者,您可以使用标准分析器(standard analyzer)、英语分析器(english analyzer)和法语分析器(french analyzer)对文本字段进行索引。
这就是多领域的目的。fields大多数字段类型通过fields参数支持多字段。
3.index
index影响字段的索引情况。
- true:字段会被索引,则可以用来进行搜索过滤。默认值就是true,只有当某一个字段的index值设置为true时,检索ES才可以作为条件去检索。
- false:字段不会被索引,不能用来搜索。
index的默认值就是true,也就是说你不进行任何配置,所有字段都会被索引。
但是有些字段是我们不希望被索引的,比如商品的图片信息(URL),就需要手动设置index为false。
4.store
是否将数据进行额外存储。
在学习Lucene时,我们知道如果一个字段的store设置为false,那么在文档列表中就不会有这个字段的值,用户的搜索结果中不会显示出来。
但是在Elasticsearch中,即便store设置为false,也可以搜索到结果。原因是Elasticsearch在创建文档索引时,会将文档中的原始数据备份,保存到一个叫做_source的属性中。而且我们可以通过过滤_source来选择哪些要显示,哪些不显示。
而如果设置store为true,就会在_source以外额外存储一份数据(多余),因此一般我们都会将store设置为false,事实上,store的默认值就是false。
在某些情况下,这对store某个领域可能是有意义的。例如,如果您的文档包含一个title、一个date和一个非常大的content字段,则可能只想检索title和date而不必从一个大_source字段中提取这些字段:
javascript">PUT /my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"store": true
},
"date": {
"type": "date",
"store": true
},
"content": {
"type": "text"
}
}
}
}
}5.boost
网站权重:网站权重是指搜索引擎给网站(包括网页)赋予一定的权威值,对网站(含网页)权威的评估评价。一 个网站权重越高,在搜索引擎所占的份量越大,在搜索引擎排名就越好。提高网站权重,不但利于网站(包括网页)在搜索引擎的排名更靠前,还能提高整站的流量,提高网站信任度。所以提高网站的权重具有相当重要的意义。 权重即网站在SEO中的重要性、权威性。英文Page Strength。
1.权重不等于排名。
2.权重对排名有着非常大的影响。
3.整站权重的提高有利于内页的排名。
新增数据时,可以指定该数据的权重,权重越高,得分越高,排名越靠前。
javascript">PUT /my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"boost": 2
},
"content": {
"type": "text"
}
}
}
}
}title字段上的匹配项的权重是字段上的匹配项的权重的两倍content ,默认boost值为1.0 。 提升仅适用于Term查询(不提升prefix、range和模糊查询)。
四. 一次创建索引库和类型
传统方式创建索引库和设置类型分为两个步骤。
第一步:创建索引库。
javascript">PUT /yx第二步:对索引库添加类型。
javascript">PUT yx/_mapping/goods
{
"properties": {
"title": {
"type": "text",
"index": true,
"store": true
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": "false"
},
"price": {
"type": "float",
"index": true,
"store": true
}
}
}刚才的案例中我们是把创建索引库和类型分开来做,其实也可以在创建索引库的同时,直接制定索引库中的类型,基本语法见下:
javascript">put /索引库名
{
"settings": {
"索引库属性名": "索引库属性值"
},
"mappings": {
"类型名": {
"properties": {
"字段名": {
"映射属性名": "映射属性值"
}
}
}
}
}演示示例:
javascript">PUT /ytx
{
"settings": {},
"mappings": {
"goods": {
"properties": {
"title": {
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_max_word"
},
"images": {
"type": "keyword",
"index": "false"
},
"price": {
"type": "float",
"index": true,
"store": true
}
}
}
}
}响应结果:
javascript">{
"acknowledged": true,
"shards_acknowledged": true,
"index": "ytx"
}五. 结语
学完本章节是不是感觉收获满满,关于Elasticsearch中的类型和映射相关的内容咱们就分享到这里。赶紧来回顾下这一章节主要学习的内容,首先我们给大家介绍了如何来创建字段映射,然后重点介绍了在Elasticsearch中几种重要的字段数据类型,最后学习了如何创建索引和类型。内容很多,还需要好好复习回顾哦。
今天的内容就分享到这里吧。关注「袁庭新」,干货天天都不断!