组件介绍
1、Elasticsearch:
是基于一个Lucene的搜索引擎,提供搜索,分析。存储数据三大功能,他提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
2 、Logstash
主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。
3、Kibana
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持,它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
4、Kafka:
数据缓冲队列。作为消息队列解耦合处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
- 1.发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 2.以容错持久的方式存储记录流。
- 3.处理记录发生的流。
5、Filebeat:
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具:
- 1.Packetbeat(搜集网络流量数据)
- 2.Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。通过从操作系统和服务收集指标,帮助您监控服务器及其托管的服务。)
- 3.Filebeat(搜集文件数据)
- 4.Winlogbeat(搜集 Windows 事件日志数据)
Elasticsearch集群部署
服务器
注:以下为环境所需所有服务器,配置为测试环境配置。
| 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|
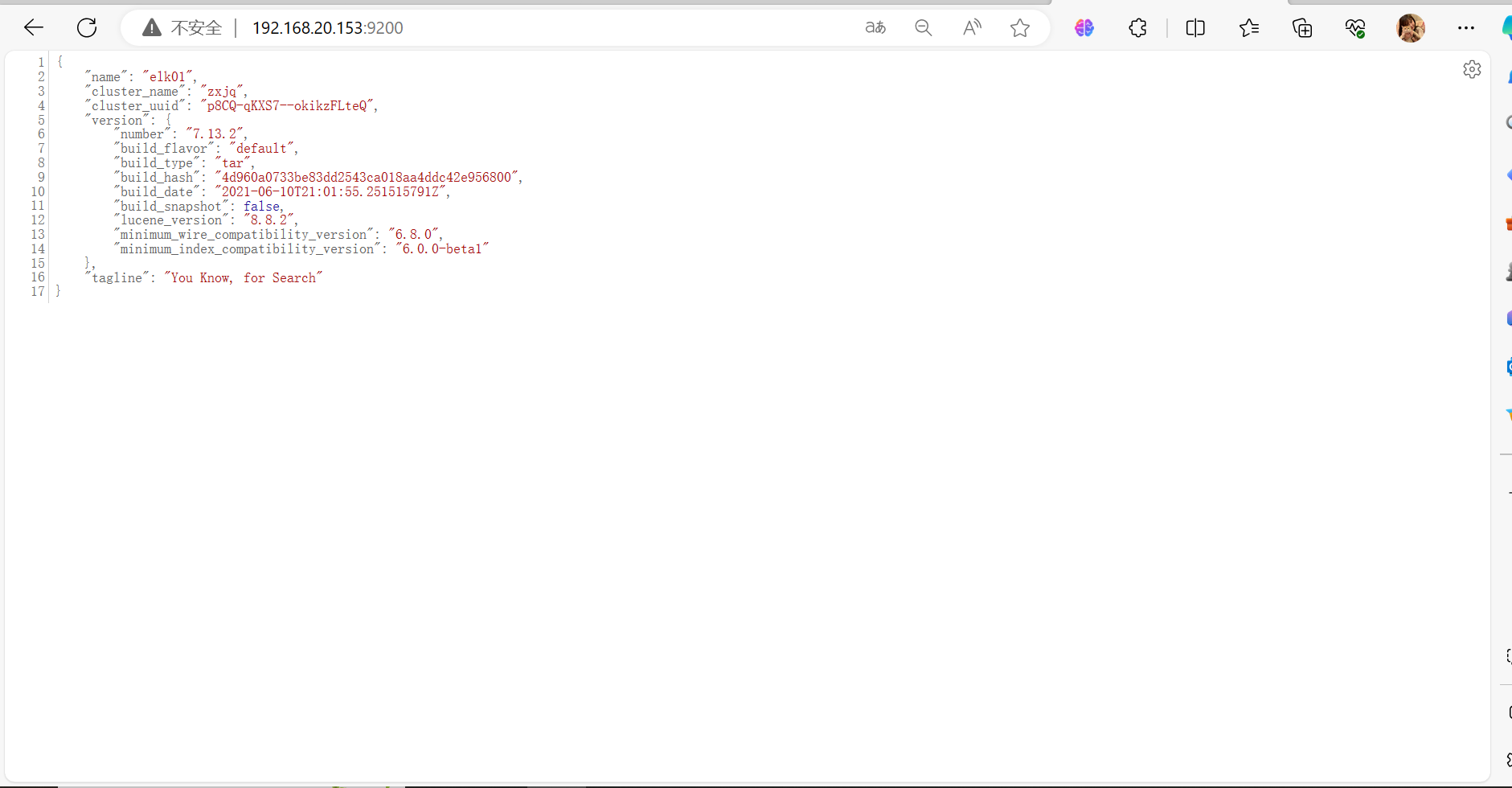
| Elk | 192.168.20.153 | centos7.5.1804 | 2核4G |
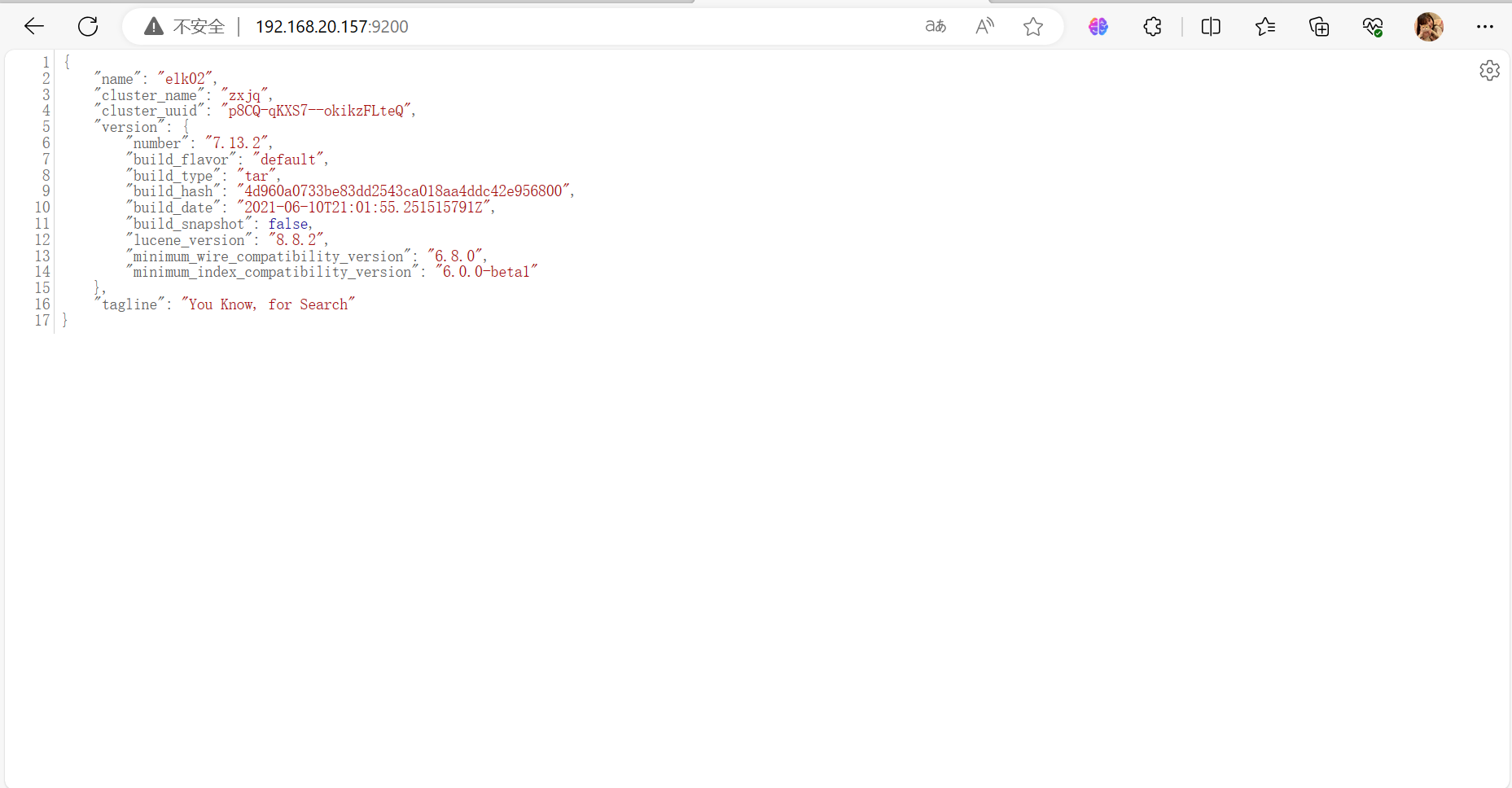
| Es1 | 192.168.20.157 | centos7.5.1804 | 2核4G |
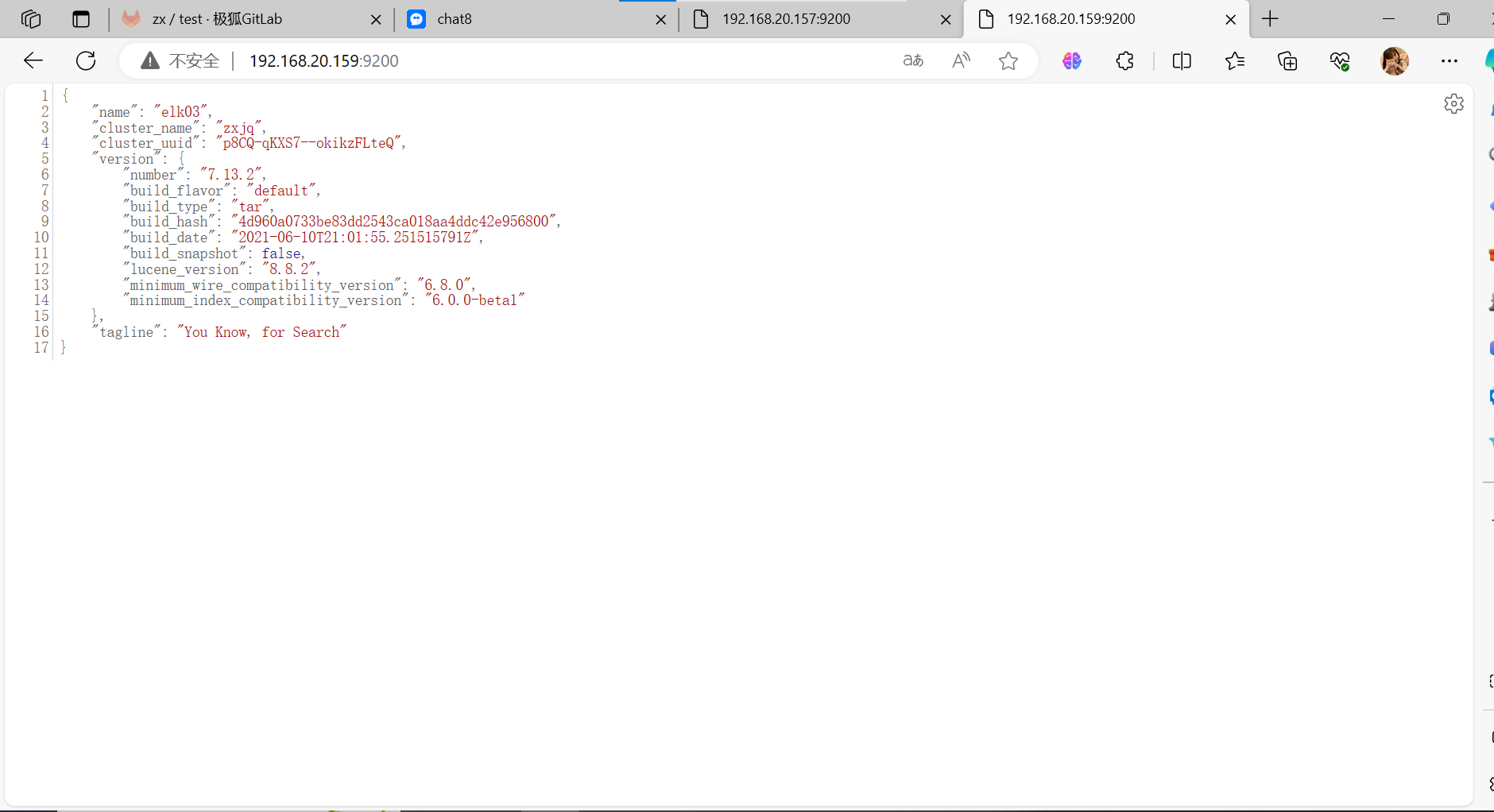
| Es2 | 192.168.20.159 | centos7.5.1804 | 2核4G |
安装配置ES
创建用户
#创建用户
[root@elk ~]# useradd es
[root@elk ~]# echo "123456" | passwd --stdin "es"
更改用户 es 的密码 。
passwd:所有的身份验证令牌已经成功更新。
安装ES
#上传解压安装包
[root@elk ~]# tar -xf elasticsearch-7.13.2-linux-x86_64.tar.gz -C /usr/local
[root@elk ~]# cd /usr/local
[root@elk local]# mv elasticsearch-7.13.2/ es
修改配置文件
[root@elk local]# cd es/config
[root@elk config]# cp elasticsearch.yml elasticsearch.yml.back
[root@elk config]# vim /usr/local/es/config/elasticsearch.yml
cluster.name: zxjq
cluster.initial_master_nodes: ["192.168.20.153","192.168.20.157", "192.168.20.159"]
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.20.157", "192.168.20.159"]
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping_timeout: 150s
discovery.zen.fd.ping_retries: 10
client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.name 集群名称,各节点配成相同的集群名称。
cluster.initial_master_nodes 集群ip,默认为空,如果为空则加入现有集群,第一次需配置
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data 数据存储目录。
path.logs 日志存储目录。
bootstrap.memory_lock 内存锁定,是否禁用交换,测试环境建议改为false。
bootstrap.system_call_filter 系统调用过滤器。
network.host 绑定节点IP。
http.port rest api端口。
discovery.seed_hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能,这里填写除了本机的其他ip
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址
创建数据和日志目录
[root@elk config]# mkdir -p /data/elasticsearch/data
[root@elk config]# mkdir -p /data/elasticsearch/logs
设置JVM堆大小 #7.0默认为4G
[root@elk config]# sed -i 's/## -Xms4g/-Xms4g/' /usr/local/es/config/jvm.options
[root@elk config]# sed -i 's/## -Xmx4g/-Xmx4g/' /usr/local/es/config/jvm.options
修改安装目录及存储目录权限
[root@elk config]# chown -R es.es /data/elasticsearch
[root@elk config]# chown -R es.es /usr/local/es
确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。
如果系统内存足够大,将堆内存最大和最小值设置为31G,因为有一个32G性能瓶颈问题。
堆内存大小不要超过系统内存的50%
系统优化
(1)增加最大文件打开数
永久生效方法
[root@elk ~]# echo "* soft nofile 65536" >> /etc/security/limits.conf
(2)增加最大进程数
[root@elk ~]# echo "* soft nproc 65536" >> /etc/security/limits.conf
更多的参数调整可以直接用这个

(3)增加最大内存映射数
[root@elk ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf
[root@elk ~]# sysctl -p
[root@elk ~]# vim /etc/security/limits.conf
* hard nofile 65536
启动ES
[root@elk config]# su - es
上一次登录:五 11月 24 17:56:53 CST 2023pts/0 上
[es@elk ~]$ cd /usr/local/es
[es@elk es]$ ./bin/elasticsearch