一、快速入门
上面的查询文档都是依赖kibana,在浏览器页面使用DSL语句去查询es,如何用java去查询es里面的文档(数据)呢
我们通过match_all查询来演示基本的API,注意下面演示的是 'match_all查询,也叫基础查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器

在进行下面的操作之前,确保你已经看了前面 '实用篇-ES-RestClient操作文档' 学的 '1. RestClient案例准备',然后在进行下面的操作
第一步: 在src/test/java/cn.itcast.hotel目录新建HotelSearchTest类,写入如下
package cn.itcast.hotel;
import cn.itcast.hotel.service.IHotelService;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
public class HotelIndexTest2 {
private RestHighLevelClient client;
@Autowired
private IHotelService hotelService;
@Test
void init(){
System.out.println(client);
}
@BeforeEach
void setUp(){
this.client = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.229.129:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
@Test
void testMatchAll() throws IOException {
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
request.source().query(QueryBuilders.matchAllQuery());
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
}
}
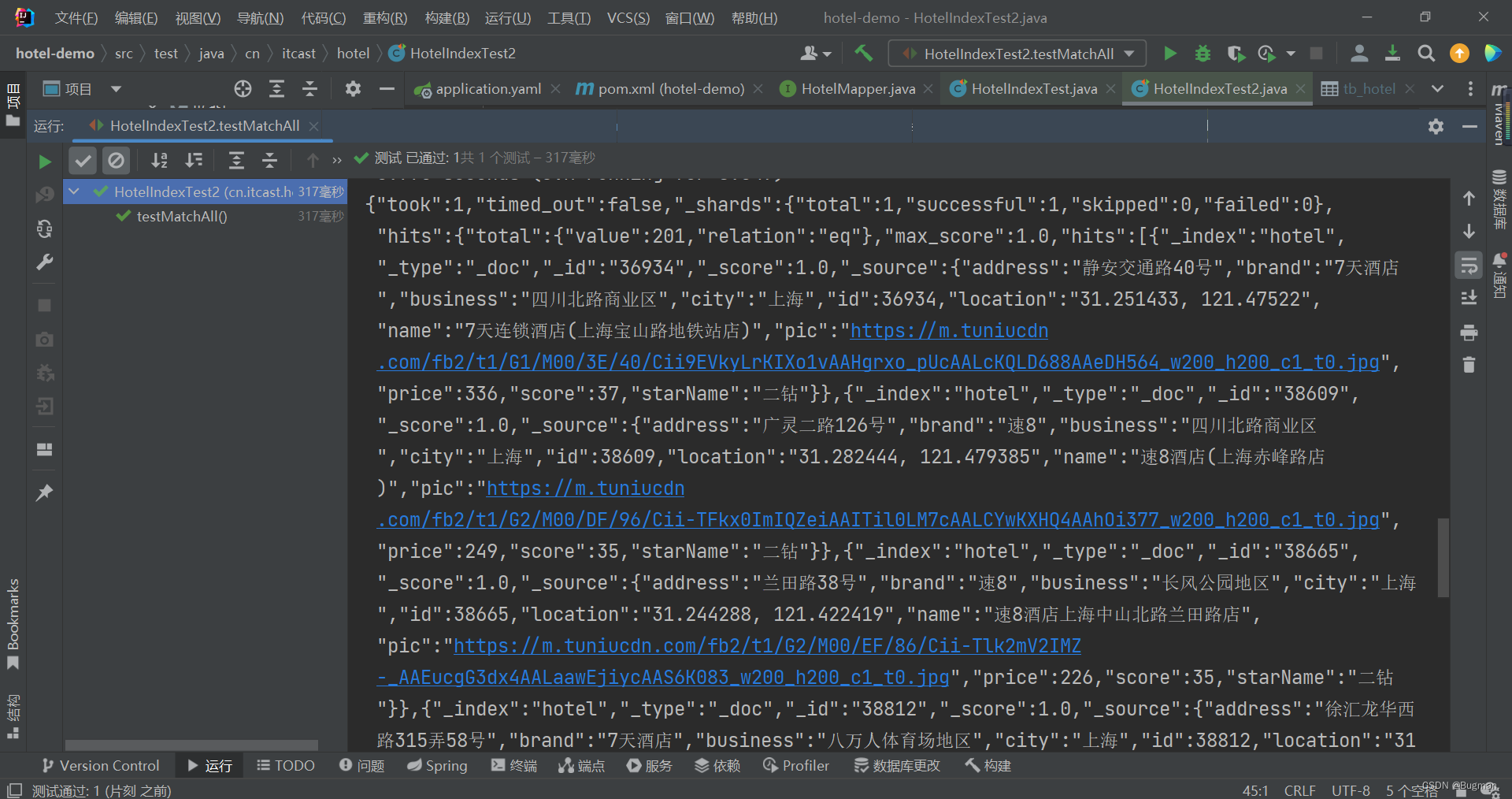
第二步: 把控制台里面我们需要的数据解析出来。返回的数据很多,我们主要是解析hits里面的数据就行了

把HotelSearchTest类修改为如下,主要的修改是sout之前做了一次解析,拿到我们想要的数据
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
public class HotelIndexTest2 {
private RestHighLevelClient client;
@Autowired
private IHotelService hotelService;
@Test
void init(){
System.out.println(client);
}
@BeforeEach
void setUp(){
this.client = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.229.129:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
@Test
void testMatchAll() throws IOException {
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
request.source().query(QueryBuilders.matchAllQuery());
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//下面为逐层解析json数据
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共有" + total + "条数据");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//反系列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
}
二、match的三种查询

我们刚刚在第一节演示的是 match_all(也叫基本查询) 查询,下面将演示 match(也叫单字段查询) 和 multi_match(也叫多字段查询) 查询
【match 查询,也叫单字段查询】
在HotelSearchTest类添加如下
@Test
void testMatch() throws IOException {
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
request.source().query(QueryBuilders.matchQuery("name","如家"));
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//下面为逐层解析json数据
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共有" + total + "条数据");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//反系列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
【multi_match 查询,也叫多字段查询】
在HotelSearchTest类添加如下
@Test
void testMatch() throws IOException {
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
request.source().query(QueryBuilders.multiMatchQuery("如家","name","business"));
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//下面为逐层解析json数据
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共有" + total + "条数据");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//反系列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}

总结: 要构建查询条件,只要记住一个QueryBuilders类即可
三、解析代码的抽取
我们发现对于 match、multi_match、match_all 查询,的解析部分的代码都是相同的,所以我们可以对解析部分的代码进行抽取,如下
快捷键ctrl + alt + M
private void handleResponse(SearchResponse response) {
//下面为逐层解析json数据
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共有" + total + "条数据");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//反系列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}之后我们在test中只专注于json的获取,解析的任务交给这段代码
四、bool和term、rang精确查询
原理同上

我们直接演示bool复合查询
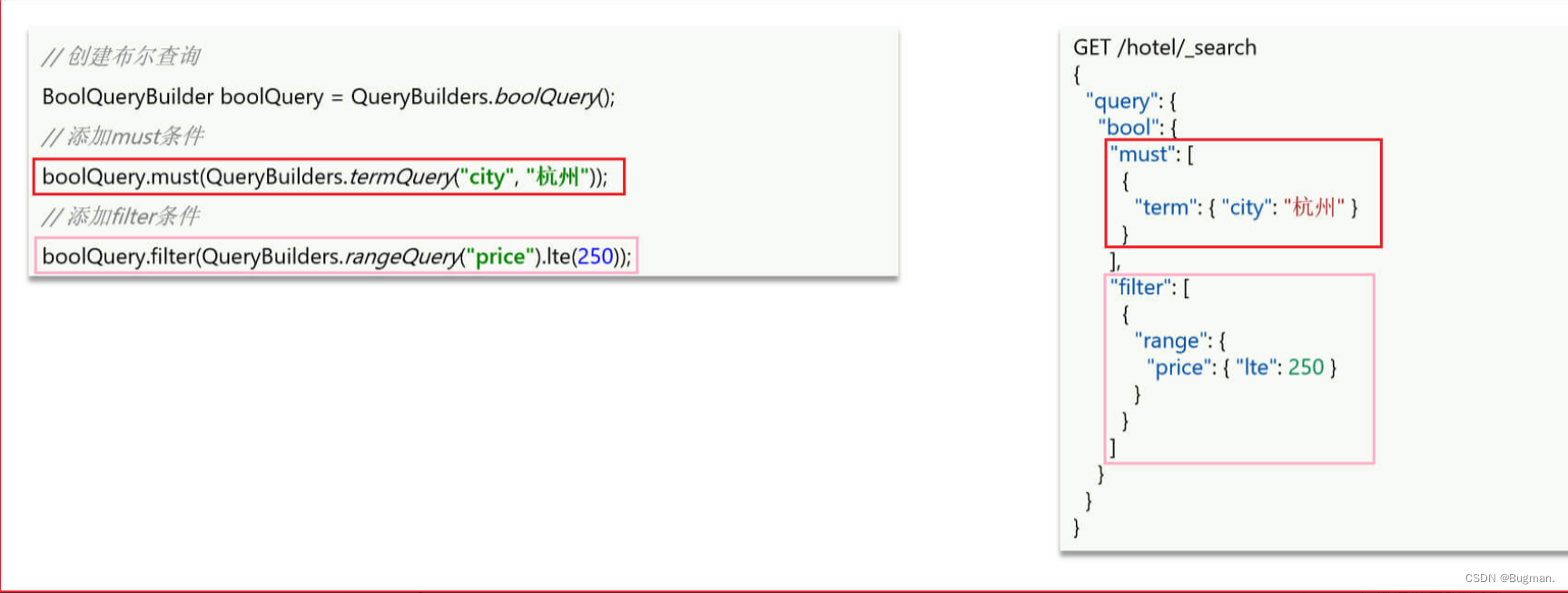
@Test
void testBool() throws IOException {
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("city","杭州"));
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}五、排序和分页

@Test
void testPageAndSort() throws IOException {
int pageNum = 1;
int pageSize = 5;
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
//查询所有
request.source().query(QueryBuilders.matchAllQuery());
//排序
request.source().sort("price", SortOrder.ASC);
//分页
request.source().from(pageNum - 1).size(pageSize);
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
handleResponse(response);
}
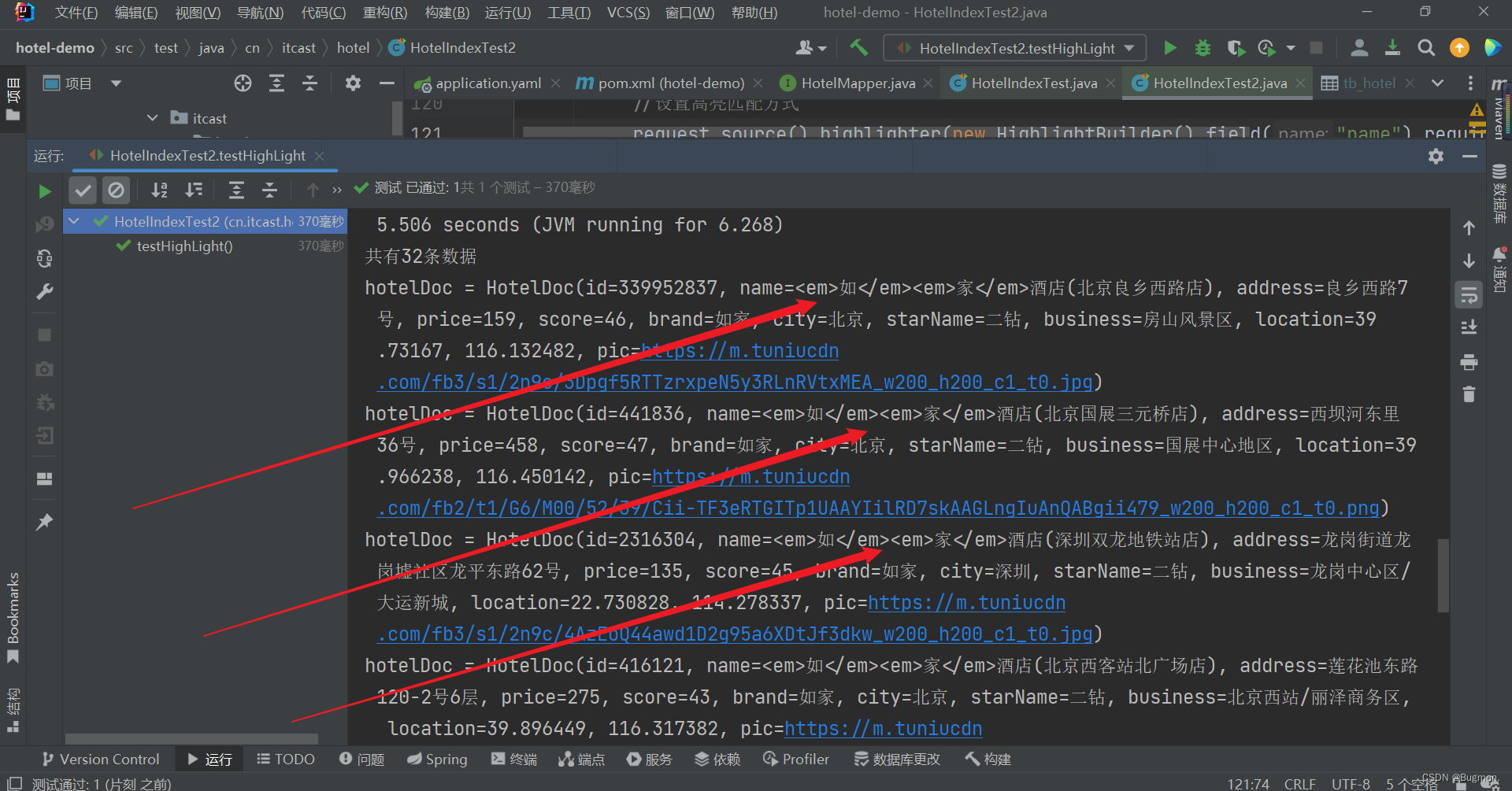
六、高亮显示
高亮API包括请求DSL构建和结果解析两部分,API和对应的DSL语句如下图,下图只是构建,再下面还有解析,高亮必须由构建+解析才能实现
解析,如下图
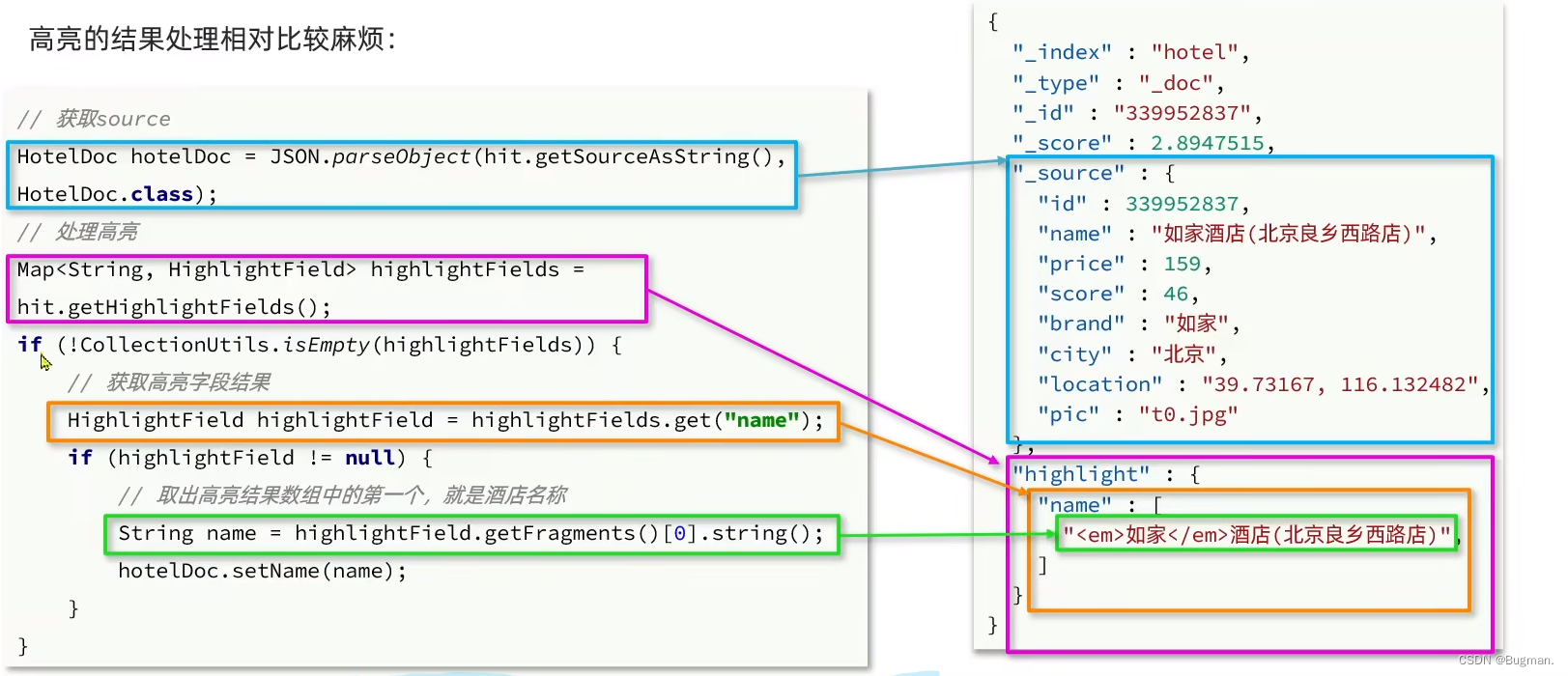
@Test
void testHighLight() throws IOException {
//准备Request
SearchRequest request = new SearchRequest("hotel");
//组织DSL参数
//查询所有
request.source().query(QueryBuilders.matchQuery("name","如家"));
//设置高亮匹配方式
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
//发送请求,得到响应结果
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//下面为逐层解析json数据
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共有" + total + "条数据");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//反系列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//解析,获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if(!CollectionUtils.isEmpty(highlightFields)){
//根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
//判断高亮字段不为空
if(highlightField!=null){
//获取高亮值
String name = highlightField.getFragments()[0].string();
//覆盖非高亮结果
hotelDoc.setName(name);
}
}
//最终输出
System.out.println("hotelDoc = " + hotelDoc);
}
}