作者:Tyler Perkins, Gilad Gal, Shani Sagiv, George Kobar, Michael Peterson, Aris Papadopoulos

Elastic Stack 8.10 增强了跨集群和向量搜索、数据摄取、Kibana® 和云注册。
- 配置远程搜索时获得更大的灵活性,并提供更多信息来分类问题,从而促进跨集群搜索。
- 通过为每个分片分配多个线程来加速向量搜索。 维度高达 2048 的嵌入模型现已正式发布。
- 在 Kibana 中,你可以使用数据比较视图检测数据中的漂移,不仅分析日志率的峰值,还分析日志率的下降,按多个值过滤热图和分区图,并将变化点检测图表添加到仪表板。
此外,借助 Elastic® 8.10,我们可以与几乎所有第三方安全集成,因为我们向 Webhook 连接器添加了客户端证书支持,并使用 Elastic Agent 将应用程序数据流式传输到 Kafka 代理。 最后,当你在云中注册时,即可开始使用你选择的云市场,并轻松链接到 AWS、Google Cloud 和 Azure!
这些新功能使客户能够:
- 在某些情况下执行向量搜索速度更快
- 更轻松地配置和维护跨集群搜索
- 分析日志率的峰值和谷值
- 使用 Webhook 连接器安全地摄取数据
Elastic Stack 8.10 现已在 Elastic Cloud 上推出,这是唯一包含最新版本中所有新功能的托管 Elasticsearch® 产品。
Elastic 8.10 中还有哪些新增功能? 查看 8.10 公告博客了解更多>>
跨集群异步搜索提供有关远程搜索状态的更多信息
当你想要对数据提出问题并将数据保留在原处时,请使用跨集群搜索 (CCS)。 我们继续改进 8.10 中的体验,提供有关每个远程集群上发生的情况的更多信息,这在搜索过程中出现任何问题时将很有帮助。 以前,搜索响应指示搜索了多少远程集群,以及跳过了多少远程集群。
搜索之前的响应集群部分:
…
"_clusters": {
"total": 3,
"successful": 2,
"skipped": 1
},
…此前,尚不清楚哪些集群被跳过或为何被跳过。 现在,CCS 响应包括来自每个远程集群的更多状态信息。 _clusters 部分有一个新的详细信息部分,其中包含每个集群(远程和本地)的条目。 它包括状态信息、分片记帐计数器以及在搜索发生时增量更新的错误信息。
8.10 中的搜索响应集群部分:
…
"_clusters": {
"total": 3,
"successful": 2,
"skipped": 1,
"details": {
"(local)": {
"status": "successful",
"indices": "*,blogs",
"took": 12050,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
}
},
"remote2": {
"status": "skipped",
"indices": "blogs,web_traffic",
"timed_out": false,
"failures": [
{
"shard": -1,
"index": null,
"reason": {
"type": "index_not_found_exception",
"reason": "no such index [web_traffic]",
"index_uuid": "_na_",
"resource.type": "index_or_alias",
"resource.id": "web_traffic",
"index": "web_traffic"
}
}
]
},
"remote1": {
"status": "successful",
"indices": "blogs",
"took": 11755,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
}
}
}
},
…在上面的示例中,你将看到名为 remote2 的远程集群被跳过,因为它没有 web_traffic 索引。 与以前一样,当远程集群在堆栈管理的远程集群屏幕中将skip_unavailable 设置为 true 时,可以跳过远程集群。
每个集群上的搜索状态可以是正在运行、成功(successful)、部分(partial)、已跳过(skipped)或失败(failed)。 在适用的情况下,你将能够查看每个集群花费了多长时间以及有多少分片完成搜索和/或失败。
要在 Kibana 中查看此额外信息,请使用检查功能查看:请求,然后单击响应选项卡:

我们希望在未来的版本中在 Kibana UI 中更显着地公开这些附加信息。
从跨集群搜索中排除集群
那么,如果其中一个远程集群遇到了糟糕的一天,需要很长时间才能响应或在跨集群搜索中提供分片错误,该怎么办? 就像你已经可以使用减号符号排除索引一样,现在你可以以相同的方式排除远程集群。
例如:
POST logs*,*:logs*,-remote4:*,-remote1*:*/_async_search这将导致搜索除 remote4 和 remote1、remote11、remote12、remote13 等之外的所有远程集群... 请注意,排除远程集群时,必须在索引名称位置使用通配符。
你仍然可以排除远程集群上的索引子集。 要排除 remote5 上的 logs-002 索引:
POST logs*,*:logs*,-remote4:*,-remote1*:*,remote5:-logs-002/_async_search连接远程集群的新安全模型
跨集群搜索 (CCS) 和跨集群复制 (CCR) 依赖于与远程集群的底层连接。 此连接受到保护,以确保恶意用户无法任意访问数据。
在 Elasticsearch 8.10 中,我们引入了新安全模型的测试版,该模型具有基于 API 密钥的身份验证和授权。 集群管理员现在在定义数据访问控制策略时具有更高的安全性和灵活性:他们可以限制对每个集群的不同索引集的访问,并且可以在远程集群受到损害的不良情况下确保更好的安全性。
2048 维 kNN 搜索 GA
Elasticsearch 支持基于 HNSW 的 kNN 向量搜索,搜索最多 2048 维(浮点 32 或字节大小)的向量,但仅使其 GA 搜索最多 1024 维的向量,在技术预览中保留 1025 到 2048 的向量。 在 8.10 中,我们正在对高达 2048 维的向量进行 kNN 向量搜索 GA。
延迟 GA 的原因是我们希望在 Lucene 中实现一个支持自定义维数的长期解决方案。 我们坚信 Lucene 会成为一般搜索(特别是向量搜索)的最佳基础设施,我们宁愿为此做出贡献,也不愿在 Lucene 之外开发它。 我们没有通过增加维度来解决任何可扩展性问题,但需要一些时间和精力才能就此达成共识。 在此之前,我们很好地在技术预览版中发布了此功能,因为我们知道我们希望以某种方式支持它,但我们想要一种我们有信心在正式发布之前能够在 Lucene 中长期运行的方式。 如果需求增加,我们将进一步研究增加维度。
向量搜索并发性改进
过去我们曾被要求改进查询的并行化(例如 #80693)。 我们的方法侧重于同时运行多个查询时的并行化(即针对高查询吞吐量进行优化)。 这意味着我们较少关注单个查询的并行化。 我们最近意识到,在某些使用模式中,并行化每个查询是有利的。 在 8.10 中,我们从并行化 kNN 向量搜索开始。
到目前为止,查询每个分片最多可以获得一个线程。 从 8.10 开始,如果线程池中有足够的可用线程,Elasticsearch 将在 kNN 向量搜索中为每个段分配最多一个线程。 当存在许多段和可用硬件时,这在基于 HNSW 的 kNN 向量搜索中尤其重要。 在我们的每天基准测试中,我们发现每个查询的查询延迟从 96 毫秒下降到 50 毫秒。

解释 log 速率下降
在 8.10 中,我们继续增强 Elastic 的 AIOps 功能,旨在为可操作的可观察性提供越来越智能的工具。 以前,你可以使用我们的日志率分析功能来检测和分析日志率峰值。 在 8.10 中,我们添加了对下降执行相同操作的功能。 因此,你现在可以调查并解释两个方向的变化。
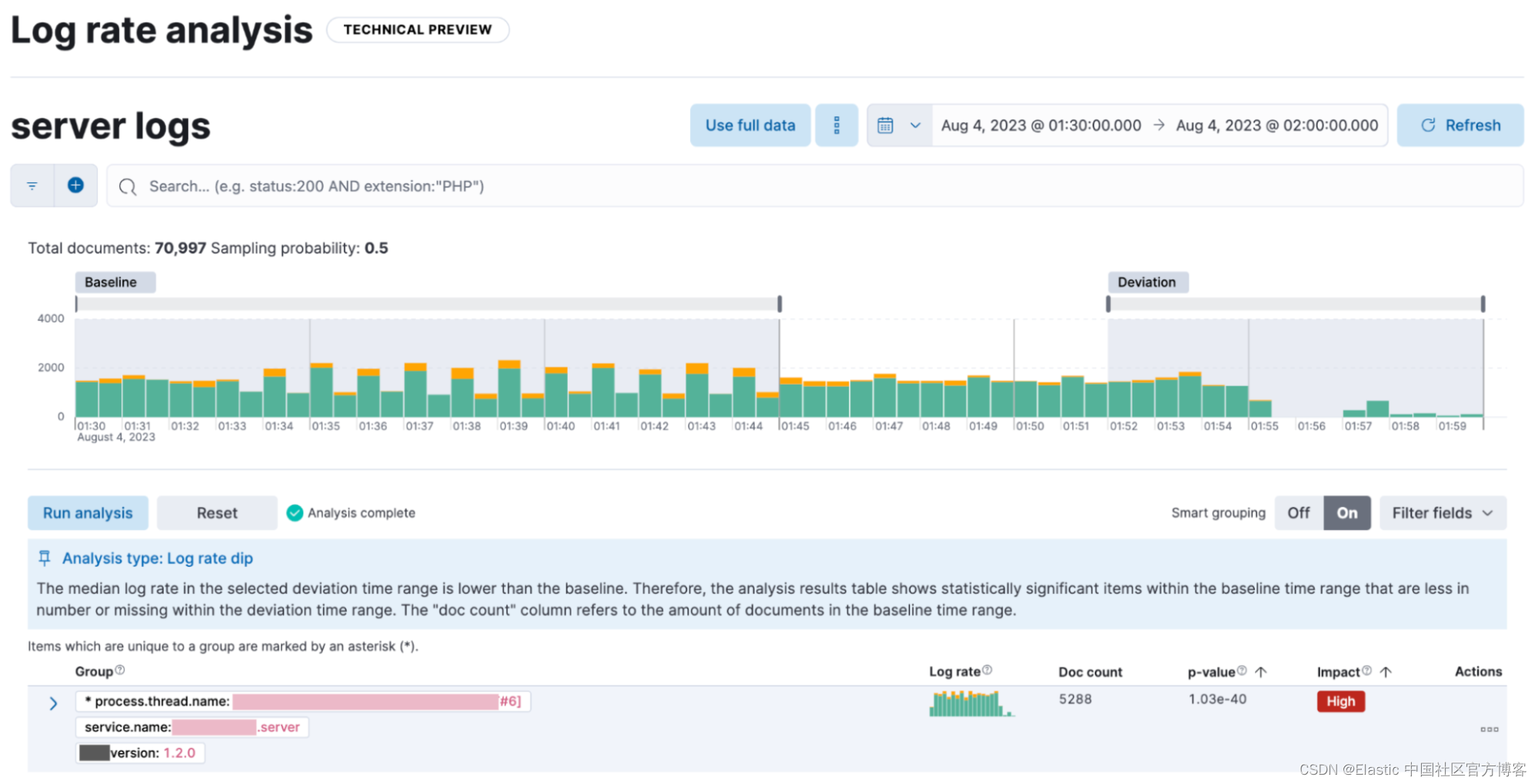
日志速率分析可帮助你通过识别字段值对来解释日志速率的下降和峰值,这些字段值对在选定的时间范围内与其基线发生情况相比显示出统计上显着的偏差(即下降时下降,峰值时上升)。 用户可以调整所选的基线和偏差时间范围,并且可以选择使用字段分组选项,该选项将倾向于同时出现的偏差字段显示在一起。 UI 提供了变化的极端程度(p 值)的衡量标准。 日志率分析可以帮助从简单地检测变化转变为关联事件并只需单击几下即可识别根本原因。 在 8.10 中,此功能处于技术预览版。
数据比较视图
数据漂移(data drift)是实际机器学习中最重要的考虑因素之一。 如果有足够的时间,数据集的统计属性预计会维持一定程度的变化。 这是因为数据源和收集数据的基础设施都是动态的。 一个重要的含义是,如果过去你使用已经发生漂移的数据训练模型,那么这些模型现在正在针对已经发生变化的世界进行优化的预测。 换句话说,一定程度的数据漂移是不可避免的,它最终可能会对模型的性能产生负面影响。
在 8.10 中,我们在 ML Data Visualizer 菜单中引入了数据比较视图,以帮助你检测数据漂移。 在 UI 上选择参考和比较时间范围,然后运行数据比较以查看值是否有显着变化,以及哪些数字和分类字段。 UI 可以衡量每个字段的变化强度(p 值),并提供参考分布和比较分布的并排视觉比较。 通过展开结果列表中的每个字段,你可以查看参考和比较窗口的值分布的详细信息。 在 8.10 中,此功能处于技术预览版。

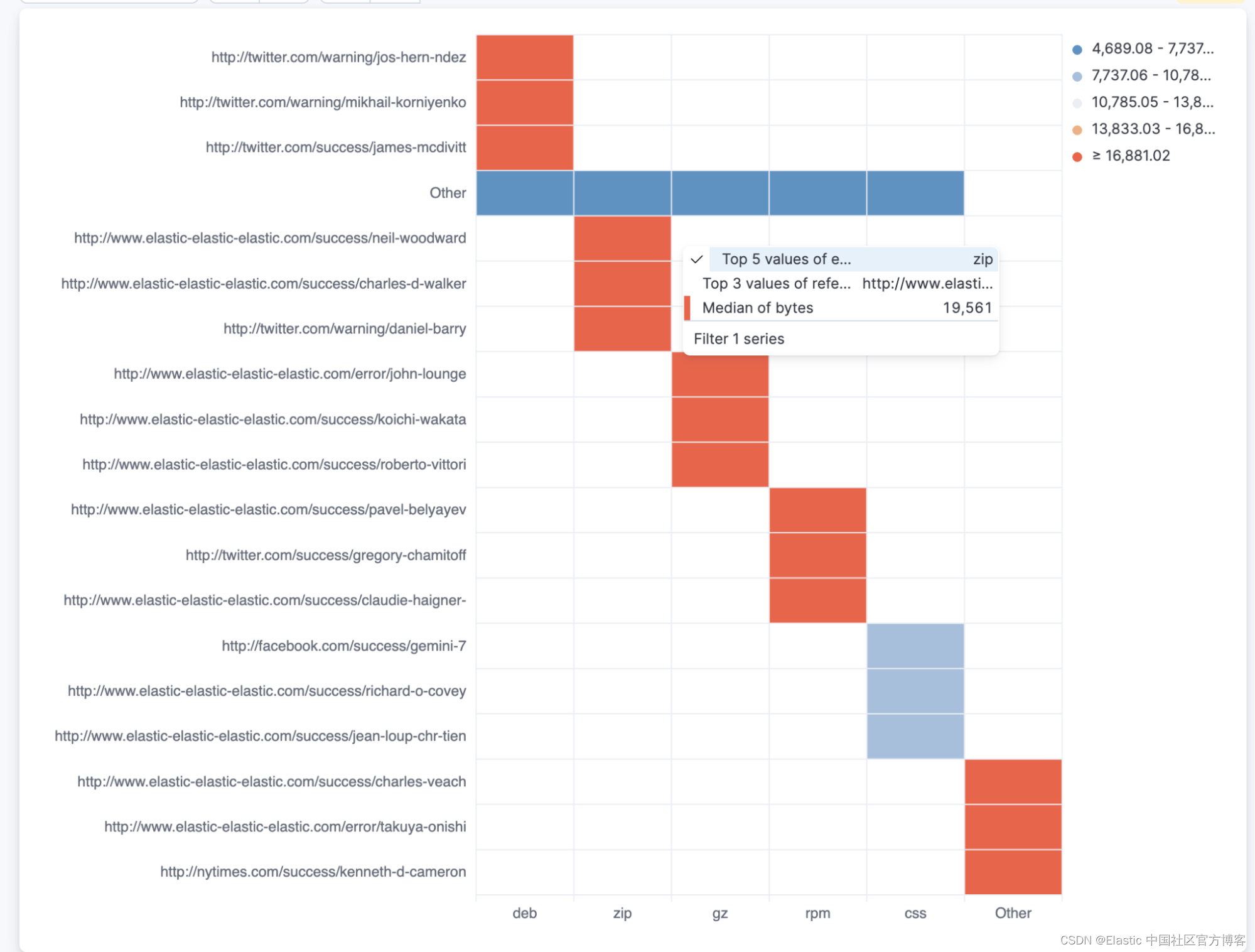
使用工具提示(tooltips)操作进行多值过滤
使用工具提示操作的多值过滤已针对 XY 图表启用,我们现在也针对热图和分区图启用它。 你现在可以同时按多个值过滤这些值,从而更轻松地在数据中找到所需的见解。
例如,你可以按地区和国家/地区过滤热图。 你还可以按产品和日期过滤分区图。
要使用多值过滤,请右键单击图表以显示工具提示菜单。 然后选择要过滤的值,然后单击 “Filter X Series”。 未来我们将继续添加对其他类型图表的多值过滤的支持。
通过分区图上的工具提示进行多值过滤:

通过热图上的工具提示进行多值过滤:
Webhook 连接器改进
组织使用安全身份验证与第三方集成是很常见的。 目前,大多数可用连接器都基于基本身份验证(用户和密码或令牌),这可能不够,并且可能违反组织安全策略。 在此版本中,Webhook 连接器得到增强,支持客户端认证,因此用户可以利用 Webhook 连接器与第三方进行安全集成。

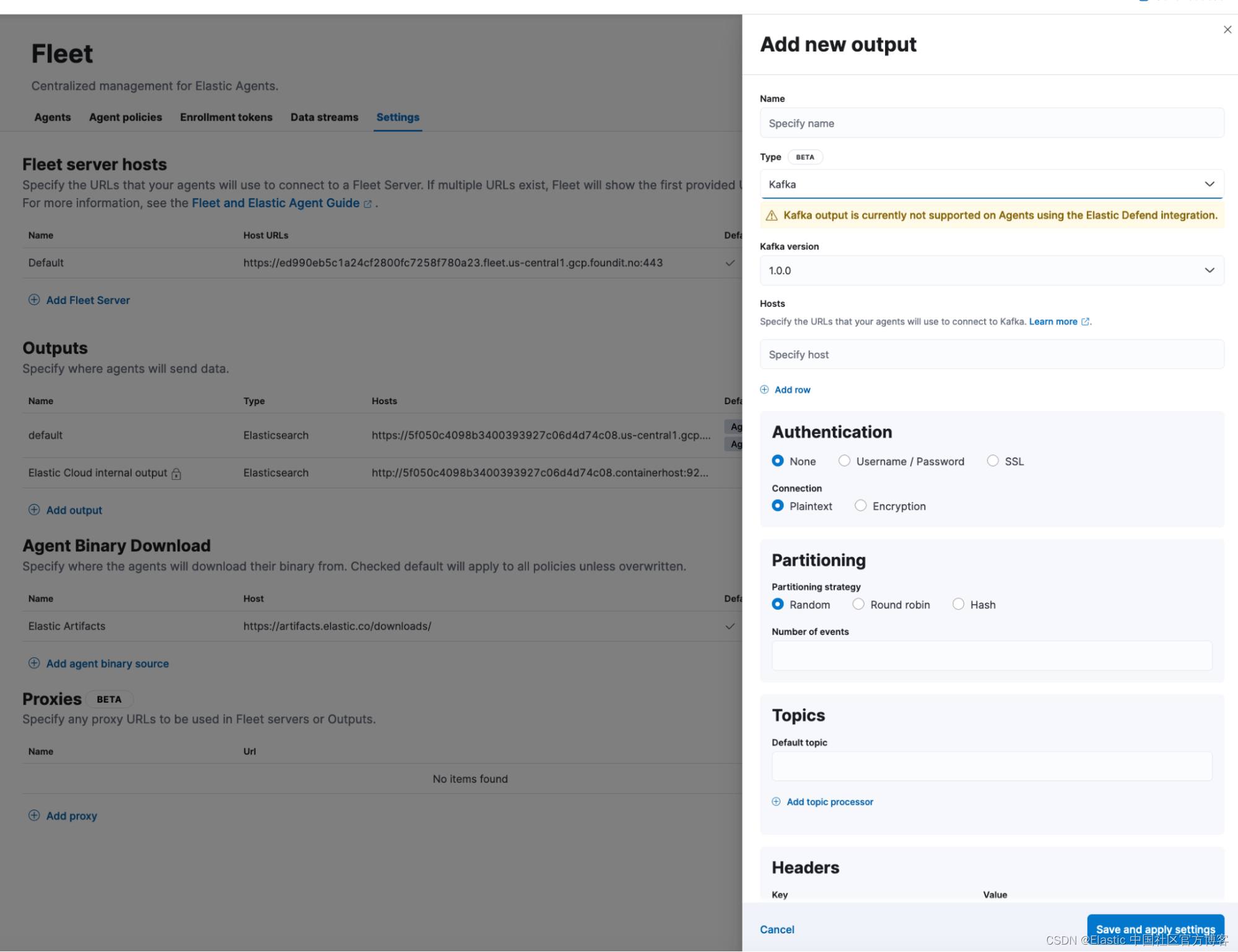
受益于 Elastic Agent 的 Kafka 输出支持
Elastic Agent 用户现在可以将数据流式传输到 Kafka 进行进一步处理(测试版中提供)。 Kafka 用于构建实时流数据管道。 用户现在可以使用 Elastic Agents 将应用程序数据流式传输到 Kafka 代理,并利用其弹性和存储功能。
同义词 API - Synonyms API
新的同义词 API 允许通过对集群的简单 API 调用来管理同义词。 它不再需要管理同义词文件、更新完整的同义词文件或将其分发到不同的节点。 不用说,更新同义词时不会中断服务。 也许最重要的是可以轻松创建、读取、更新和删除单个同义词集。 同义词是相关性排名的重要机制,通常它们是主题专家影响搜索和相关性排名的最重要选项。 现阶段,我们正在 Beta 状态下引入同义词 API,并初步计划在不久的将来将其变为 GA。
等等 ... 还有更多!
从 8.10 发布公告博客中查看搜索、可观察性或安全性方面的哪些其他增强功能可能与你相关! 有关上述功能的更多信息,请参阅 8.10 Elasticsearch 的新增功能和 8.10 Kibana 的新增功能。 最后,发布说明将为你提供 Elastic 8.10 提供的所有增强功能的完整列表。
试试看
现有 Elastic Cloud 客户可以直接从 Elastic Cloud 控制台访问其中许多功能。 没有利用云上的 Elastic? 开始免费试用。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Elastic Stack 8.10: Simpler cross-cluster search and authentication, and more | Elastic Blog