文章目录
- @[toc]
- 1.ApacheStreamPark是什么?
- 2.介绍
- 2.1 特性
- 2.2 架构
- 2.3 Zeppelin和StreamPark的对比
- 3.相关连接
- 4.部署
- 4.1 二进制包编译构建
- 4.2 镜像构建
- 4.3 初始化sql
- 4.4 部署
- 4.4.1 Docker-compose.yaml部署脚本
- 4.4.2 配置文件准备
- 4.4.3 flink启动配置
- 4.4.4 streampark启动配置
- 4.4.5 遇到的问题
- 5 cdc实践
-
- 6.资料
- 7.streampark官方提供的最新的二进制试用包
- 8.总结
文章目录
- @[toc]
- 1.ApacheStreamPark是什么?
- 2.介绍
- 2.1 特性
- 2.2 架构
- 2.3 Zeppelin和StreamPark的对比
- 3.相关连接
- 4.部署
- 4.1 二进制包编译构建
- 4.2 镜像构建
- 4.3 初始化sql
- 4.4 部署
- 4.4.1 Docker-compose.yaml部署脚本
- 4.4.2 配置文件准备
- 4.4.3 flink启动配置
- 4.4.4 streampark启动配置
- 4.4.5 遇到的问题
- 5 cdc实践
- 6.资料
- 7.streampark官方提供的最新的二进制试用包
- 8.总结
1.ApacheStreamPark是什么?
ApacheStreamPark是流处理极速开发框架,流批一体 & 湖仓一体的云原生平台,一站式流处理计算平台。
2.介绍
2.1 特性
特性中的简单易用和文档详尽这两点我也是深有体会的,部署一点都不简单,照着官方文档都不一定能搞出来,下面部署环节慢慢来吐槽吧。
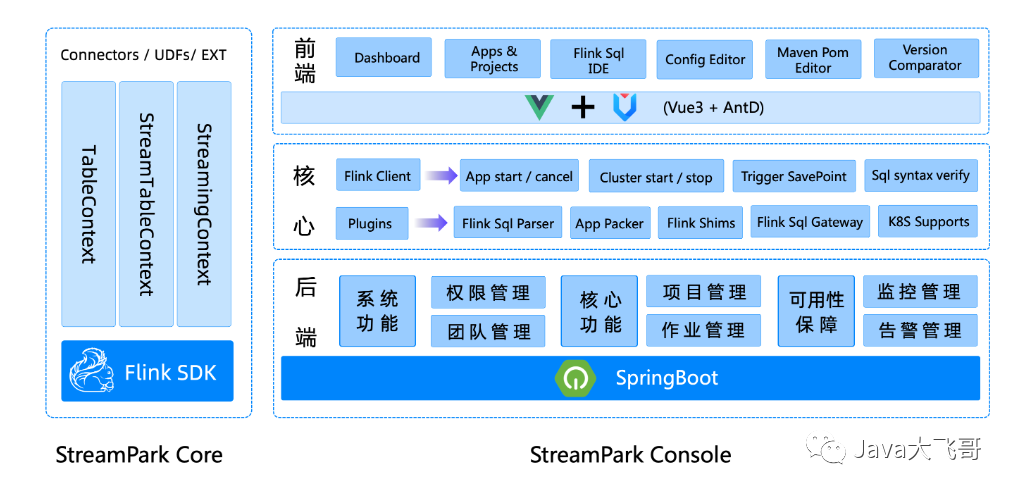
2.2 架构
2.3 Zeppelin和StreamPark的对比
之前我们写 Flink SQL 基本上都是使用 Java 包装 SQL,打 jar 包,提交到 S3 平台上。通过命令行方式提交代码,但这种方式始终不友好,流程繁琐,开发和运维成本太大。我们希望能够进一步简化流程,将 Flink TableEnvironment 抽象出来,有平台负责初始化、打包运行 Flink 任务,实现 Flink 应用程序的构建、测试和部署自动化。
这是个开源兴起的时代,我们自然而然的将目光投向开源领域中:在一众开源项目中,经过对比各个项目综合评估发现 Zeppelin 和 StreamPark 这两个项目对 Flink 的支持较为完善,都宣称支持 Flink on K8s ,最终进入到我们的目标选择范围中,以下是两者在 K8s 相关支持的简单比较。
| 功能 | Zeppelin | StreamPark |
|---|---|---|
| 任务状态监控 | 稍低 ,不能作为任务状态监控工具 | 较高 |
| 任务资源管理 | 无 | 有 ,但目前版本还不是很健全 |
| 本地化部署 | 稍低 ,on K8s 模式只能将 Zeppelin 部署在 K8s 中,否则就需要打通 Pod 和外部网络,但是这在生产环境中很少这样做的 | 可以本地化部署 |
| 多语言支持 | 较高 ,支持 Python/Scala/Java 多语言 | 一般 ,目前 K8s 模式和 YARN 模式同时支持 FlinkSQL,并可以根据自身需求,使用 Java/Scala 开发 DataStream |
| Flink WebUI 代理 | 目前还支持的不是很完整 ,主开发大佬目前是考虑整合 Ingress | 较好 ,目前支持 ClusterIp/NodePort/LoadBalance 模式 |
| 学习成本 | 成本较低 ,需要增加额外的参数学习,这个和原生的 FlinkSQL 在参数上有点区别 | 无成本 ,K8s 模式下 FlinkSQL 为原生支持的 SQL 格式;同时支持 Custome-Code(用户编写代码开发Datastream/FlinkSQL 任务) |
| Flink 多版本支持 | 支持 | 支持 |
| Flink 原生镜像侵入 | 有侵入 ,需要在 Flink 镜像中提前部署 jar 包,会同 JobManager 启动在同一个 Pod 中,和 zeppelin-server 通信 | 无侵入 ,但是会产生较多镜像,需要定时清理 |
| 代码多版本管理 | 支持 | 支持 |
3.相关连接
ApacheStreamPark官方文档
https://streampark.apache.org/zh-CN/
flink1.14.4官网
https://nightlies.apache.org/flink/flink-docs-release-1.14/zh
streampark2.1.0的gitHub地址
https://github.com/apache/incubator-streampark/tree/release-2.1.0
本地调试启动、编译指南
https://z87p7jn1yv.feishu.cn/docx/X4UfdZ8cdoeK8ExQ7sUc1UHknps
多业务聚合查询设计思路与实践
https://mp.weixin.qq.com/s/N1TqaLaqGCDRH9jnmhvlzg
4.部署
官方提供的在源码文件的docker-compose.yam里面的镜像是apache/streampark:latest,但是这个镜像根本用不了,之前用这个和官方提供的那几个镜像2.1.0和2.1.0,这两个镜像版本可以在dockerHub的官网上搜索到,为啥用不了呢?因为我在部署的时候用的最新的镜像,然后将源码包中的脚本文件拉下来在本地数据库里面streampark库里面执行了,然后使用官网给的镜像部署yaml后,发现容器一直在重启,然后我就看了下容器的日志,发现有关于数据库的表字段确实的报错,然后我就很是好奇和纳闷,就将确实的子段在表里面补全了,然后重启后可以启动起来,但是还是用不了,然后我就联系到官方,才得知他们的最新的镜像apache/streampark:latest里里面的jar包使用的是开发分支的开发版本,所以才会有用不了的问题,官方在源码版本、镜像版本和sql版本这方面做的对应关系上还是做的不够的,这个也是让使用者很头疼的一个问题,明明是按照官网的文档来搞的,为啥都搞不通?所以说上面的特性中的易用性和文档详尽可以说是值得让人吐槽了。
那如何解决呢?
给官方反馈了这个问题,但是官方建议使用源码构建部署,然后我突发奇想,我自己构建一个二进制的源码包,然后在构建一个镜像试一下看看给的行,于是乎就就进行了漫长的尝试之路。
4.1 二进制包编译构建
编译构建二进制可执行包,使用自己构建的二进制包构建Docker镜像,需要准备一台Linux的服务或者是虚拟机,可以正常上网即可,在该台机子上需要事先安装Git(拉取源码文件),Maven和java环境(JDK1.8),我采用的是是上传的源码包:incubator-streampark-2.1.0.tar.gz,然后解压源码包:
tar -zxvf incubator-streampark-2.1.0.tar.gz
解压到服务器上,然后进入到解压路径里面:

执行:
./build.sh
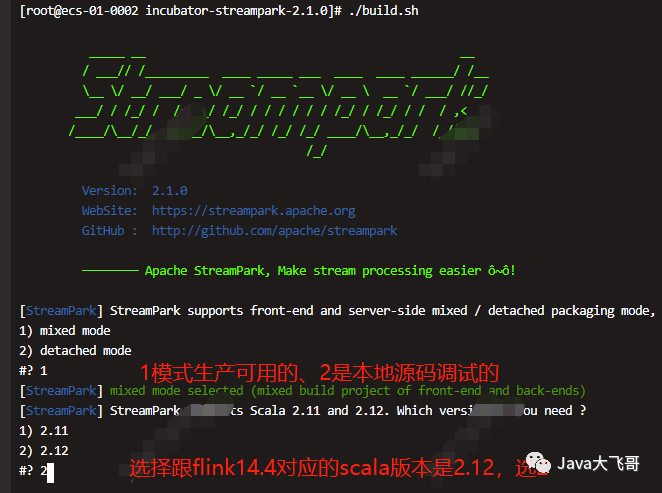
编译构建会去下载很多的pom依赖,所以需要经过漫长的等待,如果你的网络速度够快的话,估计也挺快的,然后编译构建完成后会在当前目录下看到一个dist的目录,里面就生成了一个二进制的可执行部署的源码包了:apache-streampark_2.12-2.1.0-incubating-bin.tar.gz,这里源码编译构建就构建好了,下面构建镜像需要用到这个包。
4.2 镜像构建
需要将Dockerfile文件和apache-streampark_2.12-2.1.0-incubating-bin.tar.gz放在同一个路径下(目录下)然后执行构建命令
Dockerfile文件
FROM alpine:3.16 as deps-stage
COPY . /
WORKDIR /
RUN tar zxvf apache-streampark_2.12-2.1.0-incubating-bin.tar.gz \
&& mv apache-streampark_2.12-2.1.0-incubating-bin streampark
FROM docker:dind
WORKDIR /streampark
COPY --from=deps-stage /streampark /streampark
ENV NODE_VERSION=16.1.0
ENV NPM_VERSION=7.11.2
RUN apk add openjdk8 ; \ # 这里会报错,在windows环境用;在linux上使用&&
apk add maven ; \
apk add wget ; \
apk add vim ; \
apk add bash; \
apk add curl
ENV JAVA_HOME=/usr/lib/jvm/java-1.8-openjdk
ENV MAVEN_HOME=/usr/share/java/maven-3
ENV PATH $JAVA_HOME/bin:$PATH
ENV PATH $MAVEN_HOME/bin:$PATH
RUN wget "https://nodejs.org/dist/v$NODE_VERSION/node-v$NODE_VERSION-linux-x64.tar.gz" \
&& tar zxvf "node-v$NODE_VERSION-linux-x64.tar.gz" -C /usr/local --strip-components=1 \
&& rm "node-v$NODE_VERSION-linux-x64.tar.gz" \
&& ln -s /usr/local/bin/node /usr/local/bin/nodejs \
&& curl -LO https://dl.k8s.io/release/v1.23.0/bin/linux/amd64/kubectl \
&& install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
RUN mkdir -p ~/.kube
EXPOSE 10000
构建命令:
docker build -f Dockerfile -t my_streampark:2.1.0 .
#推送阿里云镜像仓库(略)
这里给大家提供了我自己构建的镜像如下:
registry.cn-hangzhou.aliyuncs.com/bigfei/zlf:streampark2.1.0
4.3 初始化sql
执行的过程会碰到两个错误:
-- 1.Unknown column !launch' in 't flink_app'
alter table "t flink_app'
-- drop index“inx state": 2.注释这个一行
-- 这个是在2.1.0的版本里面的flink_app这个表里面缺少的字段和索引,可以或略,或者是在表里加上launch字段,不影响我我们下面部署2.1.0来使用这个库里的sql数据的
streampark库如下:
可以使用资料里面的:streampark.sql,是我执行了官方的那个sql后将streampark库导出来的一个脚本,用我给的这个也是没有问题的。
4.4 部署
4.4.1 Docker-compose.yaml部署脚本
version: '2.1'
services:
streampark-console:
image: my_streampark:2.1.0
command: ${RUN_COMMAND}
ports:
- 10000:10000
env_file: .env
volumes:
- flink:/streampark/flink/${FLINK}
- /var/run/docker.sock:/var/run/docker.sock
- /etc/hosts:/etc/hosts:ro
- ~/.kube:/root/.kube:ro
privileged: true
restart: unless-stopped
jobmanager:
image: apache/flink:1.14.4-scala_2.12-java8
command: "jobmanager.sh start-foreground"
ports:
- 8081:8081
volumes:
- ./conf:/opt/flink/conf
- /tmp/flink-checkpoints-directory:/tmp/flink-checkpoints-directory
- /tmp/flink-savepoints-directory:/tmp/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: apache/flink:1.14.4-scala_2.12-java8
depends_on:
- jobmanager
command: "taskmanager.sh start-foreground"
volumes:
- ./conf:/opt/flink/conf
- /tmp/flink-checkpoints-directory:/tmp/flink-checkpoints-directory
- /tmp/flink-savepoints-directory:/tmp/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
volumes:
flink:
这个文件是我把flink的部署和streampark的部署合并修改了下,注意不要使用streampark官网的那种方式,搞了一个桥接的网络,否则有可能导致容器间的网络不通。
4.4.2 配置文件准备
deplay文件夹下:
conf文件夹如下:
需要修改.env和conf里面的application.yaml文件里面streampark数据库相关的连接信息,这个application可以自己搞个目录挂载到容器的如下路径:
把官方的那个拿出来改一改然后挂载,我这个好像是没有生效的,
相关资料会在文末分享的。
flink_267">4.4.3 flink启动配置
flink官网内存配置
https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/memory/mem_setup_tm/
4.4.4 streampark启动配置
flink-conf.yaml文件配置
jobmanager.rpc.address: jobmanager
blob.server.port: 6124
query.server.port: 6125
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints-directory
state.savepoints.dir: file:///tmp/flink-savepoints-directory
heartbeat.interval: 1000
heartbeat.timeout: 5000
rest.flamegraph.enabled: true
web.backpressure.refresh-interval: 10000
classloader.resolve-order: parent-first
taskmanager.memory.managed.fraction: 0.1
taskmanager.memory.process.size: 2048m
jobmanager.memory.process.size: 7072m
4.4.5 遇到的问题
由于我之前搞的flink部署有点问题,使用了桥接网络,导致直接使用flink的sql-client.sh执行之前的cdc失败了,报了如下的错误:
java.net,UnknownHostException: jobmanager: Temporary failure in name resolution
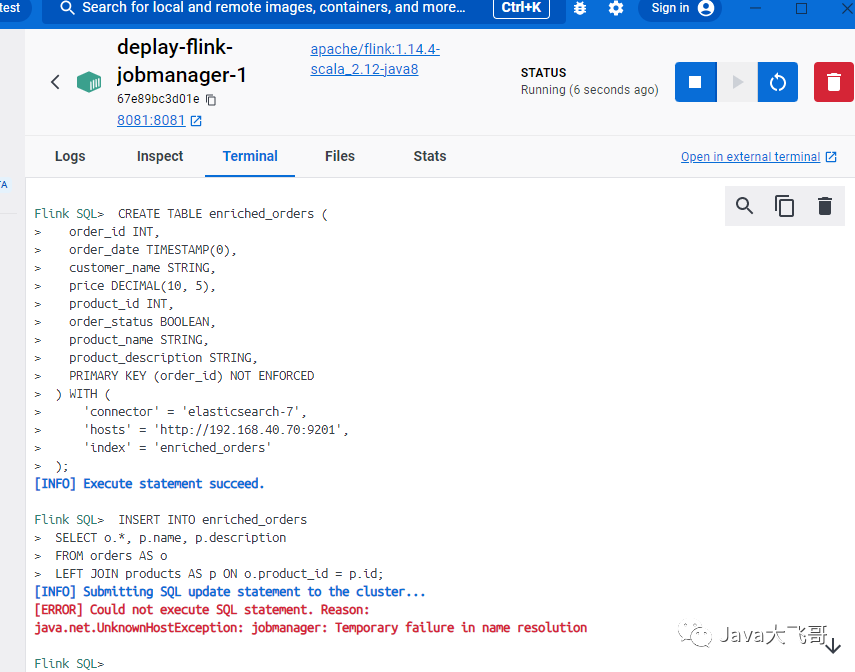
然后我就把部署文件改成上面那种方式,后面把之前启动的容器全部删除,重新部署后就可以正常执行了。
之前还遇到一个错误就是在cdc实践的时候会遇到的问题,streampark提交启动了cdc任务,但是flink的jobs里面这个任务执行失败了:
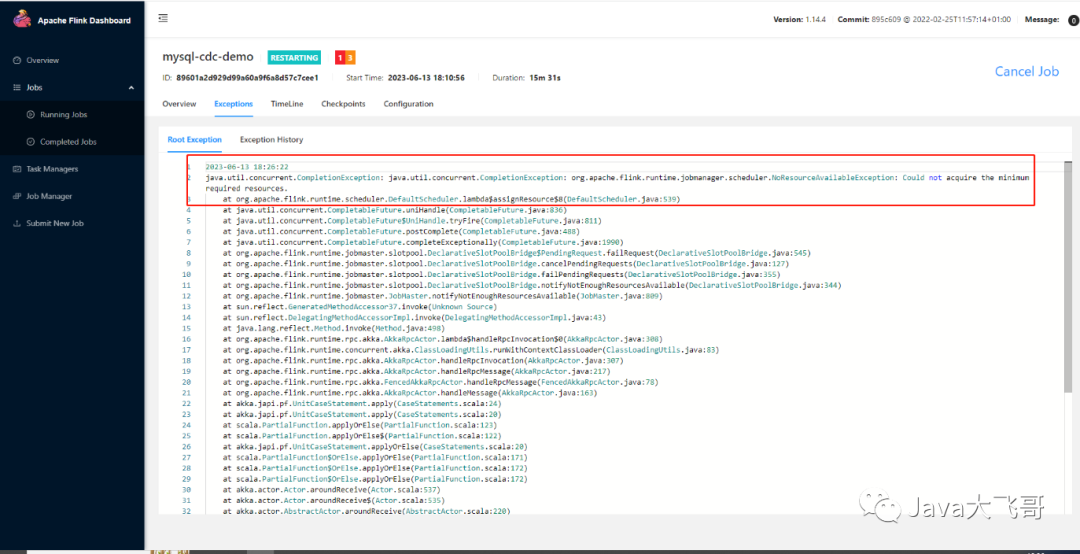
java.util.concurrent.CompletionException: java.util.concurrent.Completiotion: org.apache.flink.runtime.jobmanager.schedulerloResourceAvailableException: Could not acquire the minimurrequired resources.
这个问题是之前flink采用桥接网络搭建的有问题,导致jobmanager启动不起来,使用上面正确的启动方式和flink-conf.yaml里面的配置,对taskmanager和jobmanager的资源配置和内存配置如下:
taskmanager.memory.managed.fraction: 0.1
taskmanager.memory.process.size: 2048m
jobmanager.memory.process.size: 7072m
请根据官网先关flink的内存参数来设置,资源尽量给大点,然后把之前有问题的容器删除重新启动后,三个容器都正常启动了。
5 cdc实践
flink_340">5.1 确定flink是否正常
flink首页正常启动在没有任务执行的时候可以看到slot的数据量:

正常启动taskManagers里面可以看到task的信息:
job-manager的信息:
5.2 streampark管理端配置
streampark的默认的用户名和密码是:admin/streampark
flinkhome_362">5.2.1 flink-home配置
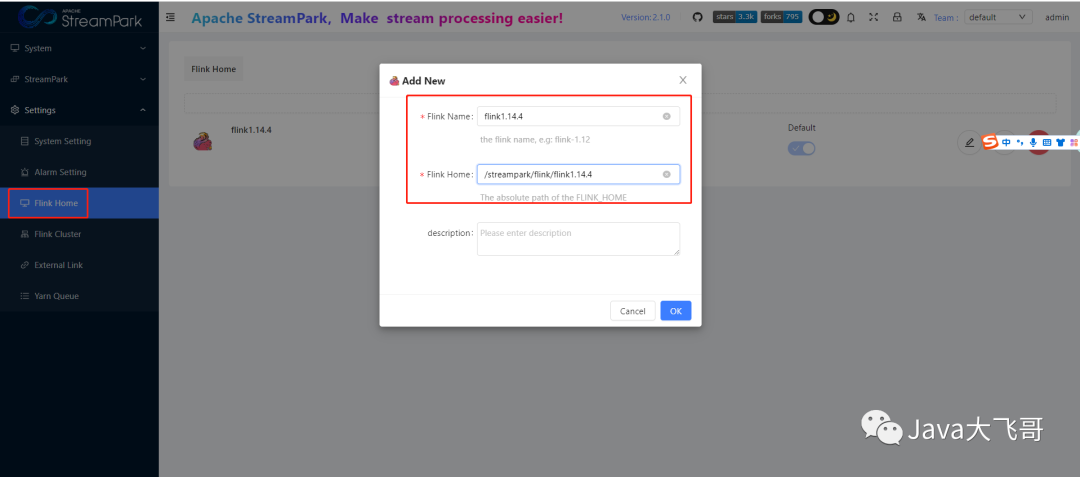
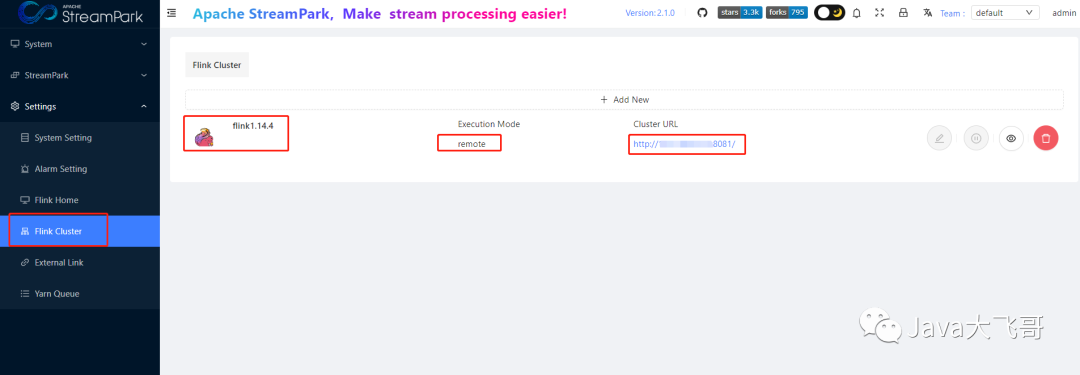
flinkcluster_368">5.2.2 flink-cluster配置
5.2.3 新增cdc-sql和上传jar或添加依赖
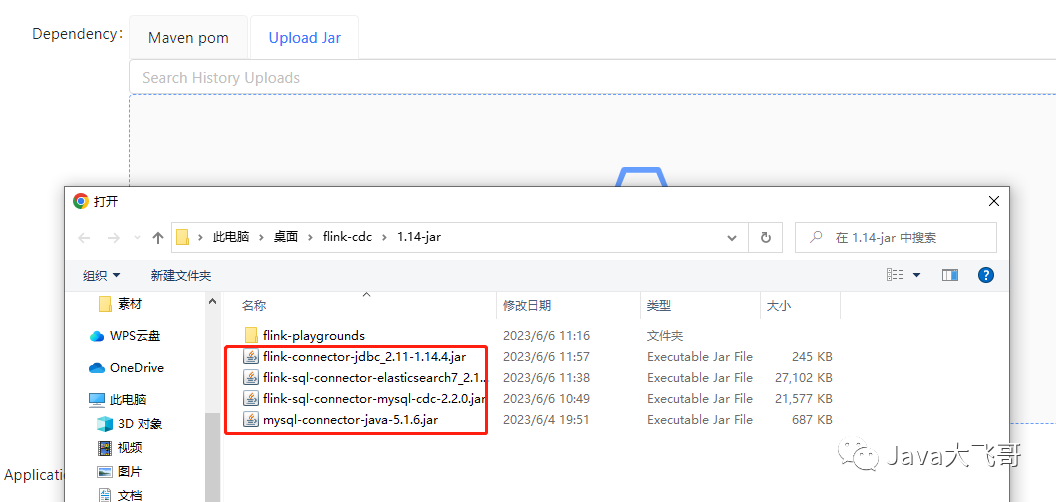
flink的job-manager节点和task-manager节点的/opt/flink/lib节点下我都传了上面那几个jar包了,然后用这个streampark来管理你只要把你任务用到的jar的上或者是把jar的maven依赖填上去,然后任务在大包的时候会将这个这些依赖全部打包到任务的jar包中,最后提交给flink去执行,这种是不是更加的方便快捷高效的管理任务了呢。
5.3 cdc执行成功实例
cdc相关的请看
多业务聚合查询设计思路与实践
https://mp.weixin.qq.com/s/N1TqaLaqGCDRH9jnmhvlzg
streampark端:
streampark点击开始启任务的时候不选择savepoint了,不然flink那边会报错的
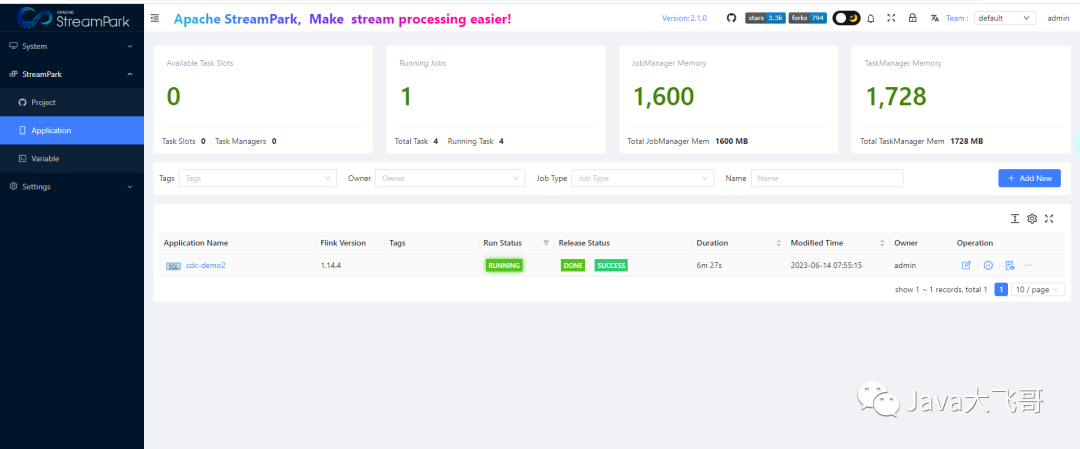
flink端:
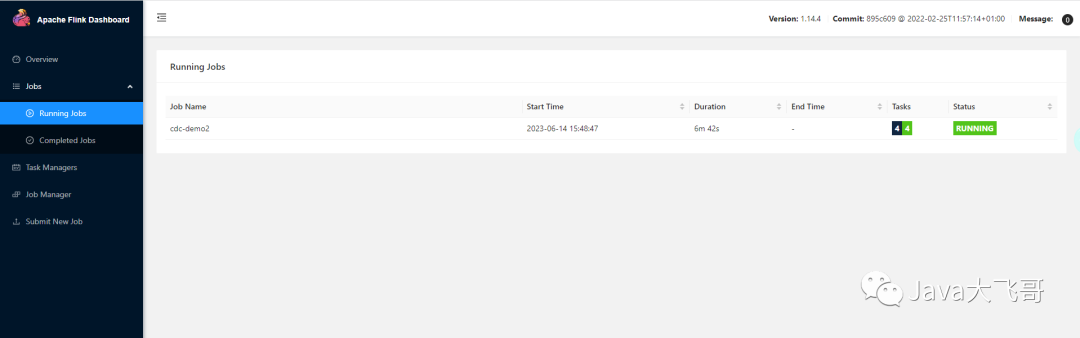
需要容器一直运行中,如果重启后之前的savepoint和chackpoint就没了,这个感觉是flink的savepoint和checkpoint的配置没有生效,还得重新研究下,如果重启了,没有之前的任务了,需要在streampark启动下flink这边就又有了。
发现一个问题就是:刚才我重新提交了,但是flink的jobmanager的时候报了这个savepoin持久化到/tmp/flink-checkpoints-directory/文件中失败了,这个有点离谱了嘛:
2023-06-14 15:48:58 2023-06-14 07:48:58,551 WARN org.apache.flink.runtime.jobmaster.JobMaster [] - Error while processing AcknowledgeCheckpoint message
2023-06-14 15:48:58 org.apache.flink.runtime.checkpoint.CheckpointException: Could not finalize the pending checkpoint 3. Failure reason: Failure to finalize checkpoint.
2023-06-14 15:48:58 at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.completePendingCheckpoint(CheckpointCoordinator.java:1227) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.receiveAcknowledgeMessage(CheckpointCoordinator.java:1100) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$acknowledgeCheckpoint$1(ExecutionGraphHandler.java:89) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$processCheckpointCoordinatorMessage$3(ExecutionGraphHandler.java:119) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_322]
2023-06-14 15:48:58 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_322]
2023-06-14 15:48:58 at java.lang.Thread.run(Thread.java:750) [?:1.8.0_322]
2023-06-14 15:48:58 Caused by: java.io.IOException: Mkdirs failed to create file:/tmp/flink-checkpoints-directory/acb95418d91e34f6cce478337154dd4f/chk-3
2023-06-14 15:48:58 at org.apache.flink.core.fs.local.LocalFileSystem.create(LocalFileSystem.java:262) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.state.filesystem.FsCheckpointMetadataOutputStream.<init>(FsCheckpointMetadataOutputStream.java:65) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.state.filesystem.FsCheckpointStorageLocation.createMetadataOutputStream(FsCheckpointStorageLocation.java:109) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.checkpoint.PendingCheckpoint.finalizeCheckpoint(PendingCheckpoint.java:323) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.completePendingCheckpoint(CheckpointCoordinator.java:1210) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:48:58 ... 6 more
2023-06-14 15:49:01 2023-06-14 07:49:01,533 INFO org.apache.flink.runtime.checkpoint.CheckpointCoordinator [] - Triggering checkpoint 4 (type=CHECKPOINT) @ 1686728941531 for job acb95418d91e34f6cce478337154dd4f.
2023-06-14 15:49:01 2023-06-14 07:49:01,557 WARN org.apache.flink.runtime.jobmaster.JobMaster [] - Error while processing AcknowledgeCheckpoint message
2023-06-14 15:49:01 org.apache.flink.runtime.checkpoint.CheckpointException: Could not finalize the pending checkpoint 4. Failure reason: Failure to finalize checkpoint.
2023-06-14 15:49:01 at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.completePendingCheckpoint(CheckpointCoordinator.java:1227) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:49:01 at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.receiveAcknowledgeMessage(CheckpointCoordinator.java:1100) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:49:01 at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$acknowledgeCheckpoint$1(ExecutionGraphHandler.java:89) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:49:01 at org.apache.flink.runtime.scheduler.ExecutionGraphHandler.lambda$processCheckpointCoordinatorMessage$3(ExecutionGraphHandler.java:119) ~[flink-dist_2.12-1.14.4.jar:1.14.4]
2023-06-14 15:49:01 at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [?:1.8.0_322]
2023-06-14 15:49:01 at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [?:1.8.0_322]
2023-06-14 15:49:01 at java.lang.Thread.run(Thread.java:750) [?:1.8.0_322]
2023-06-14 15:49:01 Caused by: java.io.IOException: Mkdirs failed to create file:/tmp/flink-checkpoints-directory/acb95418d91e34f6cce478337154dd4f/chk-4
然后我将我wsl的/tmp路径下的flink-checkpoints-directory、flink-savepoints-directory的权限重新修改下:
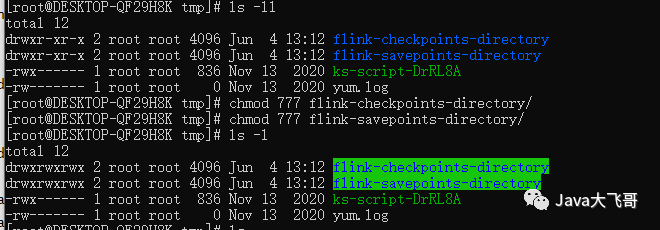
后面我又使用如下命令给两个文件夹下所有文件授权:
[root@DESKTOP-QF29H8K tmp]# chmod -R 777 flink-savepoints-directory/
[root@DESKTOP-QF29H8K tmp]# chmod -R 777 flink-checkpoints-directory/
上面两种授权都试了下,但是还是报错了,这个不晓得是不是一个bug,还是我的checkpoints、savepoints有配置的有问题,这个问题我已经反馈给官方了,估计在Linux上就没有这个问题了,在windows上确实是奇葩的问题太多了。
这个问题我知道是啥问题了,是挂载的问题,如果是linux系统是没有这个问题的,但是在windows上可以使用绝对路径和相当路径来挂载,那就跟wsl里面的文件路径没有关系了哈,然后修改部署文件docker-compose-windows.yaml 如下:
version: '2.1'
services:
streampark-console:
image: my_streampark:2.1.0
command: ${RUN_COMMAND}
ports:
- 10000:10000
env_file: .env
volumes:
- flink:/streampark/flink/${FLINK}
- /var/run/docker.sock:/var/run/docker.sock
- /etc/hosts:/etc/hosts:ro
- ~/.kube:/root/.kube:ro
privileged: true
restart: unless-stopped
jobmanager:
image: apache/flink:1.14.4-scala_2.12-java8
command: "jobmanager.sh start-foreground"
ports:
- 8081:8081
volumes:
- ./conf:/opt/flink/conf
- ./tmp/flink-checkpoints-directory:/tmp/flink-checkpoints-directory
- ./tmp/flink-savepoints-directory:/tmp/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: apache/flink:1.14.4-scala_2.12-java8
depends_on:
- jobmanager
command: "taskmanager.sh start-foreground"
volumes:
- ./conf:/opt/flink/conf
- ./tmp/flink-checkpoints-directory:/tmp/flink-checkpoints-directory
- ./tmp/flink-savepoints-directory:/tmp/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
volumes:
flink:
重新在当前部署路径下执行部署命令:
docker-compose -f docker-compose-windows.yaml up -d
docker-compose 挂载目录
https://blog.csdn.net/SMILY12138/article/details/130305102
可以看出在当前的deplay先会自动创建一个tmp文件夹,里面会自动创建flink-checkpoints-directory、flink-savepoints-directory
然后上面那个错误就没有报了,就可以正常的创建写入文件到这个两个挂载的目录中了:
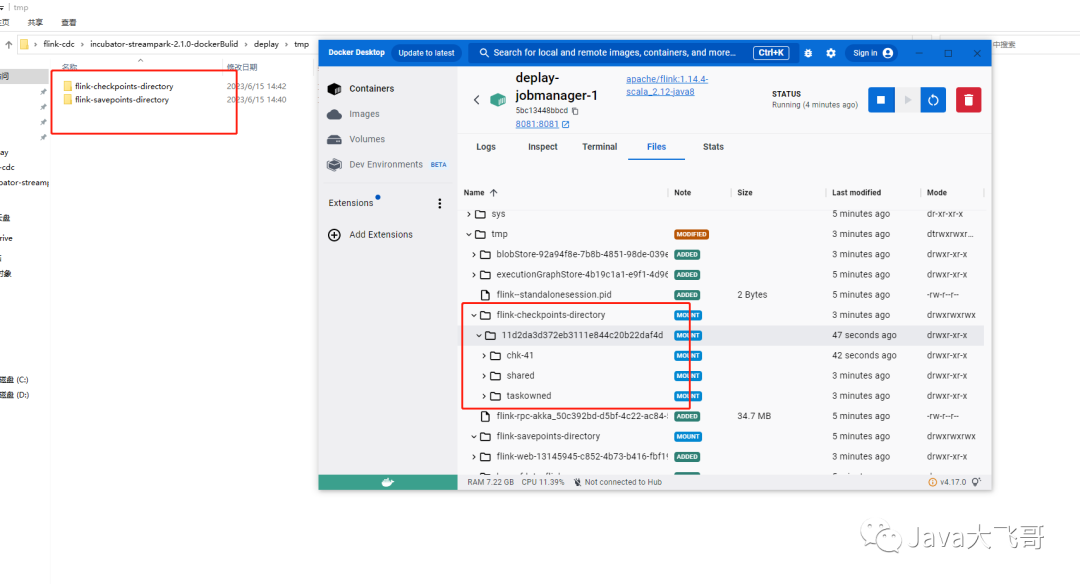
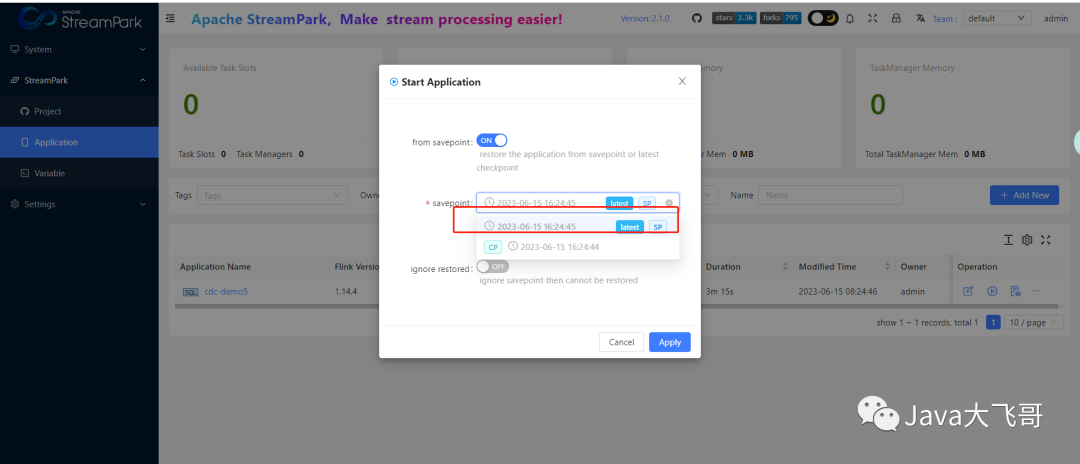
这个挂载文集解决了之后,重新启动任务就会自动提示选择checkpoint了
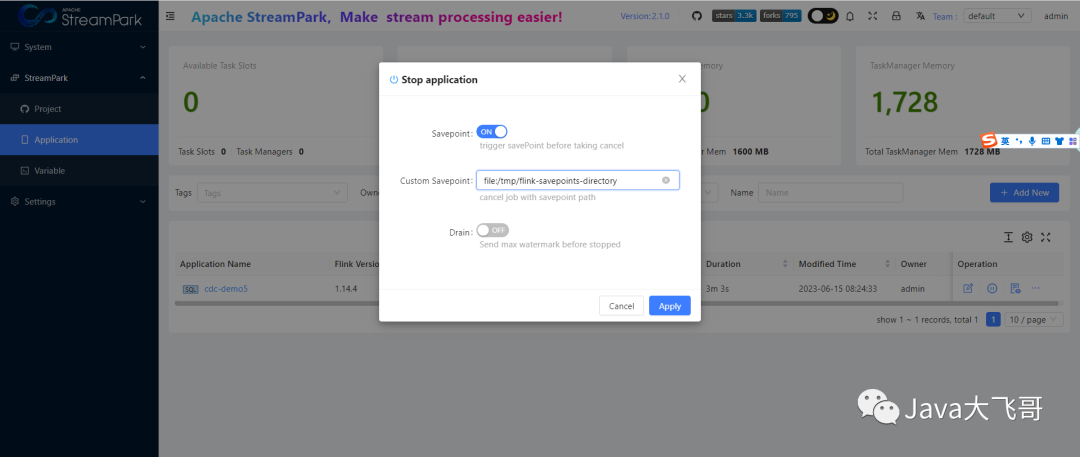
任务第一次启动的时候不设置savepoint,第一次就指定会找不到_meatedata报错,当停止任务的时候给一个savepoint的如下,然后重新启动就可以自动选择savepoint了:

# savepoint的写法是
file:/tmp/flink-savepoints-directory
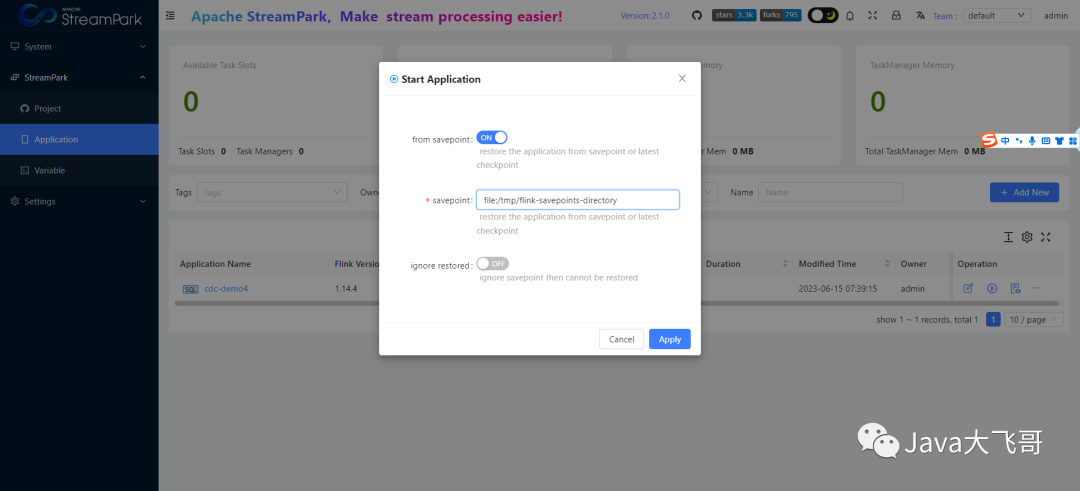
停止执行savepoint的位置:
重启选择last-savepoint启动:
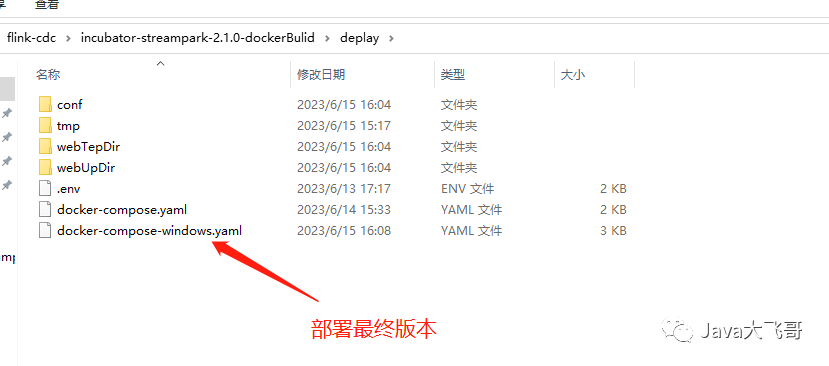
由于Linux的/tmp下重启文件会被删除,所以我重新修改了docker-compose-windows.yaml 如下,这一版本也是最终的部署版本,windows环境下可以直接使用,Linux上稍微改下也是可以使用的:
version: '2.1'
services:
streampark-console:
image: my_streampark:2.1.0
command: ${RUN_COMMAND}
ports:
- 10000:10000
env_file: .env
volumes:
- flink:/streampark/flink/${FLINK}
- /var/run/docker.sock:/var/run/docker.sock
- /etc/hosts:/etc/hosts:ro
- ~/.kube:/root/.kube:ro
privileged: true
restart: unless-stopped
jobmanager:
image: apache/flink:1.14.4-scala_2.12-java8
command: "jobmanager.sh start-foreground"
ports:
- 8081:8081
volumes:
- ./webUpDir:/usr/local/flink/upload
- ./webTepDir:/usr/local/flink/tmpdir
- ./conf:/opt/flink/conf
- ./tmp/flink-checkpoints-directory:/usr/local/flink/flink-checkpoints-directory
- ./tmp/flink-savepoints-directory:/usr/local/flink/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
taskmanager:
image: apache/flink:1.14.4-scala_2.12-java8
depends_on:
- jobmanager
command: "taskmanager.sh start-foreground"
volumes:
- ./webUpDir:/usr/local/flink/upload
- ./webTepDir:/usr/local/flink/tmpdir
- ./conf:/opt/flink/conf
- ./tmp/flink-checkpoints-directory:/usr/local/flink/flink-checkpoints-directory
- ./tmp/flink-savepoints-directory:/usr/local/flink/flink-savepoints-directory
environment:
- JOB_MANAGER_RPC_ADDRESS=jobmanager
volumes:
flink:
flink-conf.yaml新增两个配置:
jobmanager.rpc.address: jobmanager
blob.server.port: 6124
query.server.port: 6125
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints-directory
state.savepoints.dir: file:///tmp/flink-savepoints-directory
heartbeat.interval: 1000
heartbeat.timeout: 5000
rest.flamegraph.enabled: true
web.backpressure.refresh-interval: 10000
classloader.resolve-order: parent-first
taskmanager.memory.managed.fraction: 0.1
taskmanager.memory.process.size: 2048m
jobmanager.memory.process.size: 7072m
# 新增两个配置
web.upload.dir: /usr/local/flink/upload
web.tmpdir: /usr/local/flink/tmpdir
这两个配置用于配置flink的webui端上传或者临时文件做一个持久化(或者通过http的方式)提交任务的jar,streampark提交的cdc的任务会构架一个jar包然后调用flink的接口给flink上传一个jar包来执行这个任务,所以这个任务的包需要做一个持久化:
两参数的官方位置
https://nightlies.apache.org/flink/flink-docs-release-1.17/docs/deployment/config/
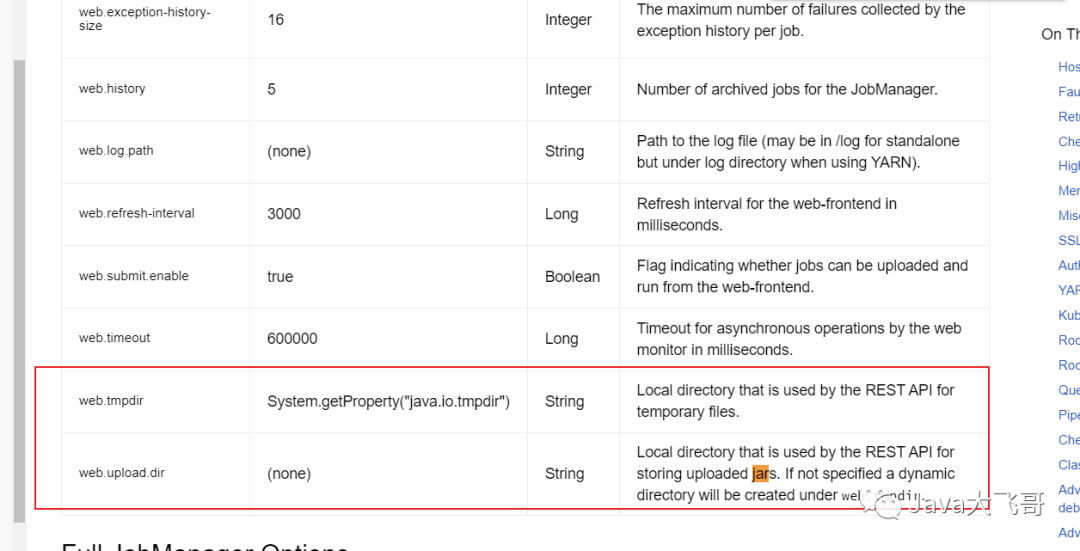
Flink standalone集群问题记录
https://blog.csdn.net/LeoGanlin/article/details/124692129
webTepDir:
webUpDir:
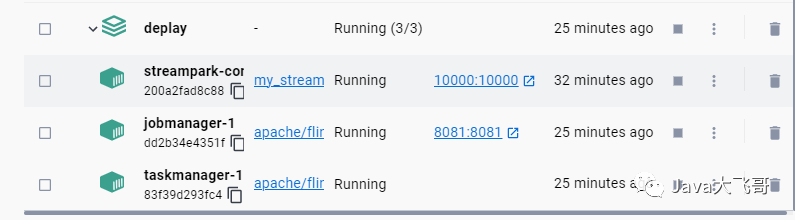
解决了savepoint和checkpoint的挂载问题和重启后flink的jar任务丢失,然后我们先停止三个容器,然后重新启动后,看flink里面的jar包任务还在的,streampark的界面的任务也是正常执行的,然后去验证cdc,去mysql客户端新增、修改和删除关联数据,在es中也是可以实时同步的;savepoint和checkpoint持久化可以使用fliesystem挂载到本机目录,或者是使用hdfs、oss、S3等等,官方都有文档说明的。
6.资料
链接:https://pan.baidu.com/s/1ajAAcjsMOxYR9-uQW0jzmw
提取码:c3nv
资料包内容:
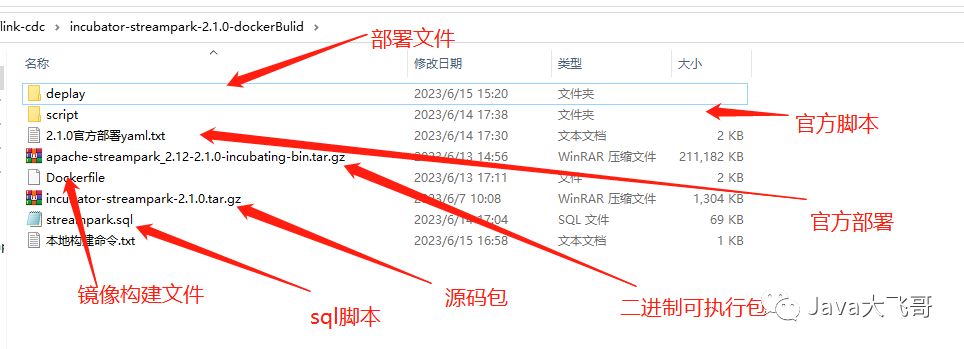
部署文件夹:
7.streampark官方提供的最新的二进制试用包
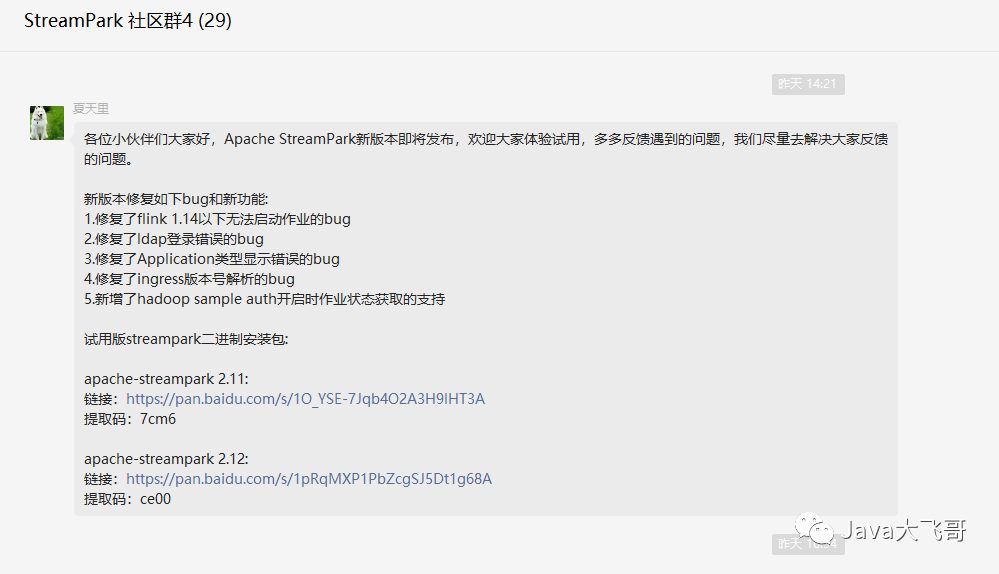
试用版streampark二进制安装包:
apache-streampark 2.11:
链接:https://pan.baidu.com/s/1O_YSE-7Jqb4O2A3H9lHT3A
提取码:7cm6
apache-streampark 2.12:
链接:https://pan.baidu.com/s/1pRqMXP1PbZcgSJ5Dt1g68A
提取码:ce00
官方虽然给我们重新搞了两个二进制试用包,不推荐使用最新的包,因为有想不到的bug和踩不完的坑,尝鲜使用下也是可以的。
8.总结
到此我的分享就结束了,在实践的过程中也遇到了很多的问题,同时在解决问题的过程中也有很多的收获,也结识了一些大佬,在和大佬交流的过程中也得到了一些启发和学到了一些东西,希望我的分享能给你带来帮助,请一键三连,么么哒!