参考:一起看看ES集群的启动流程
本文主要从流程上介绍整个集群是如何启动的,集群状态如何从Red变成Green,然后分析其他模块的流程。
这里的集群启动过程指集群完全重启时的启动过程,期间要经历选举主节点、主分片、数据恢复等重要阶段,理解其中原理和细节,对于解决或避免集群维护过程中可能遇到的脑裂、无主、恢复慢、丢数据等问题有重要作用。
集群启动的整体流程如下图所示:
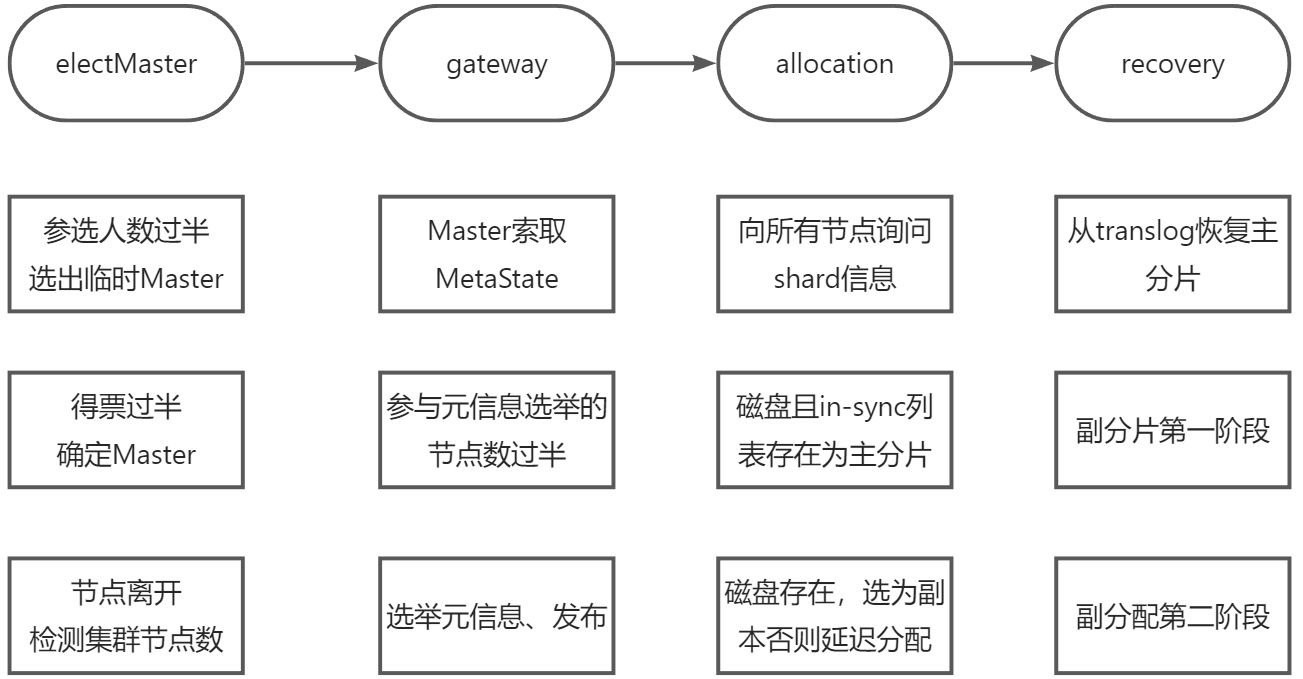
选举主节点
假设有若干节点正在启动,集群启动的第一件事是从已知的活跃机器列表中选择一个作为主节点,选主之后的流程由主节点触发。
ES的选主算法是基于Bully算法的改进,主要思路是对节点ID排序,取ID值最大的节点作为Master,每个节点都运行这个流程。
是不是非常简单?选主的目的是确定唯一的主节点,初学者可能认为选举出的主节点应该持有最新的元数据信息,实际上这个问题在实现上被分解为两步:
- 先确定唯一的、大家公认的主节点
- 再想办法把最新的机器元数据复制到选举出的主节点上。
成为主节点的条件
基于节点ID排序的简单选举算法有三个附加约定条件:
一、参选人数需要过半,达到 quorum(多数)后就选出了临时的主。
为什么是临时的?每个节点运行排序取最大值的算法,(因为网络分区或启动速度)结果不一定相同。
举个例子,集群有5台主机,节点ID分别是1、2、3、4、5。当产生网络分区或节点启动速度差异较大时,节点1看到的节点列表是1、2、3、4,选出4;节点2看到的节点列表是2、3、4、5,选出5。结果就不一致了,由此产生下面的第二条限制。
二、得票数需过半。某节点被选为主节点,必须判断加入它的节点数过半,才确认Master身份,解决第一个问题。
三、当探测到节点离开事件时,必须判断当前节点数是否过半。如果达不到 quorum,则放弃Master身份,重新加入集群。
如果不这么做,则设想以下情况:假设5台机器组成的集群产生网络分区,2台一组,3台一组,产生分区前,Master位于2台中的一个,此时3台一组的节点会重新并成功选取Master,产生双主,俗称脑裂。
集群并不知道自己共有多少个节点,quorum值从配置中读取,我们需要设置配置项:
discovery.zen.minimum_master_nodes
选举集群元信息
被选出的 Master 和集群元信息的新旧程度没有关系。
因此它的第一个任务是选举元信息,让各节点把各自存储的元信息发过来,根据版本号确定最新的元信息,然后把这个信息广播下去,这样集群的所有节点都有了最新的元信息。
集群元信息的选举有两个级别:集群级和索引级。不包含哪个shard存于哪个节点这种信息。这种信息以节点磁盘存储的为准,需要上报。为什么呢?
因为读写流程是不经过Master的,Master 不知道各shard 副本直接的数据差异。HDFS 也有类似的机制,block 信息依赖于DataNode的上报。
为了集群一致性,参与选举的元信息数量需要过半,Master发布集群状态成功的规则也是等待发布成功的节点数过半。
在选举过程中,不接受新节点的加入请求。
集群元信息选举完毕后,Master发布首次集群状态,然后开始选举shard级元信息。
allocation过程
选举shard级元信息,构建内容路由表,是在allocation模块完成的。
在初始阶段,所有的shard都处于UNASSIGNED(未分配)状态。ES中通过分配过程决定哪个分片位于哪个节点,重构内容路由表。
此时,首先要做的是分配主分片。
选主分片
现在看某个主分片[website][0]是怎么分配的。
所有的分配工作都是 Master 来做的。
- 最开始时,Master不知道主分片在哪,它向集群的所有其他节点询问,让其他节点把[website][0]分片的元信息发过来。
- Master 收到所有返回后,它就有了这个 shard 的信息,然后根据某种策略选一个分片作为主分片。
是不是效率有些低?
这种询问量=shard 数×节点数。所以说我们最好控制shard的总规模别太大。
现在有了shard[website][0]的分片的多份信息,具体数量取决于副本数设置了多少。现在考虑把哪个分片作为主分片。
ES 5.x以下的版本,通过对比shard级元信息的版本号来决定。
在多副本的情况下,考虑到如果只有一个 shard 信息汇报上来,则它一定会被选为主分片,但也许数据不是最新的,版本号比它大的那个shard所在节点还没启动。
在解决这个问题的时候,ES 5.x开始实施一种新的策略:给每个 shard 都设置一个 UUID,然后在集群级的元信息中记录哪个shard是最新的。
因为ES是先写主分片,再由主分片节点转发请求去写副分片,所以主分片所在节点肯定是最新的,如果它转发失败了,则要求Master删除那个节点。
所以,从ES 5.x开始,主分片选举过程是通过集群级元信息中记录的“最新主分片的列表”来确定主分片的:汇报
信息中存在,并且这个列表中也存在。
如果集群设置了:禁止分配分片,集群仍会强制分配主分片。
“cluster.routing.allocation.enable”: “none”
因此,在设置了上述选项的情况下,集群重启后的状态为Yellow,而非Red。
选副分片
主分片选举完成后,从上一个过程汇总的 shard 信息中选择一个副本作为副分片。
如果汇总信息中不存在,则分配一个全新副本的操作依赖于延迟配置项:
index.unassigned.node_left.delayed_timeout
我们的线上环境中最大的集群有100+节点,掉节点的情况并不罕见,很多时候不能第一时间处理,这个延迟我们一般配置为以天为单位。
最后,allocation过程中允许新启动的节点加入集群。
Index Recovery
分片分配成功后开始Recovery流程。
主分片的recovery不会等待其副分片分配成功才开始recovery。它们是独立的流程,只是副分片的recovery需要主分片恢复完毕才开始。
** 为什么需要recovery**?
对于主分片来说,可能有一些数据没来得及刷盘;对于副分片来说,一是没刷盘,二是主分片写完了,副分片还没来得及写,主副分片数据不一致。
主分片recovery
由于每次写操作都会记录事务日志(translog),事务日志中记录了哪种操作,以及相关的数据。
因此将最后一次提交(Lucene 的一次提交就是一次 fsync 刷盘的过程)之后的 translog中进行重放,
建立Lucene索引,如此完成主分片的recovery。
副分片recovery
副分片的恢复是比较复杂的,在ES的版本迭代中,副分片恢复策略有过不少调整。
副分片需要恢复成与主分片一致,同时,恢复期间允许新的索引操作。在目前的6.0版本中,恢复分成两阶段执行:
第一阶段
在主分片所在节点,获取translog保留锁,从获取保留锁开始,会保留translog不受其刷盘清空的影响。
然后调用Lucene接口把shard做快照,这是已经刷磁盘中的分片数据。把这些shard数据复制到副本节点。
在phase1完毕前,会向副分片节点发送告知对方启动engine,在phase2开始之前,副分片就可以正常处理写请求了。
第二阶段
对translog做快照,这个快照里包含从phase1开始,到执行translog快照期间的新增索引。
将这些translog发送到副分片所在节点进行重放。
由于需要支持恢复期间的新增写操作(让ES的可用性更强),这两个阶段中需要重点关注以下几个问题:
分片数据完整性
如何做到副分片不丢数据?
第二阶段的translog 快照包括第一阶段所有的新增操作。
那么第一阶段执行期间如果发生“Lucene commit”(将文件系统写缓冲中的数据刷盘,并清空translog),清除translog怎么办?
在ES 2.0之前,是阻止了刷新操作,以此让translog都保留下来。
从2.0版本开始,为了避免这种做法产生过大的translog,引入了translog.view的概念,创建 view 可以获取后续的所有操作。
从6.0版本开始,translog.view 被移除。引入TranslogDeletionPolicy的概念,它将translog做一个快照来保持
translog不被清理。这样实现了在第一阶段允许Lucene commit。
数据一致性
在ES 2.0之前,副分片恢复过程有三个阶段,第三阶段会阻塞新的索引操作,并传输第二阶段执行期间新增的translog,这个时间很短。
自2.0版本之后,第三阶段被删除,恢复期间没有任何写阻塞过程。
在副分片节点,重放translog时,phase1和phase2之间的写操作与phase2重放操作之间的时序错误和冲突,通过写流程中进行异常处理,对比版本号来过滤掉过期操作。
这样,时序上存在错误的操作被忽略,对于特定的 doc,只有最新一次操作生效,保证了主副分片一致。
checkpoint
第一阶段尤其漫长,因为它需要从主分片拉取全量的数据。
在ES6.x中,对第一阶段再次优化:标记每个操作。
在正常的写操作中,每次写入成功的操作都分配一个序号,通过对比序号就可以计算出差异范围。
在实现方式上,添加了global checkpoint 和** local checkpoint**。
主分片负责维护global checkpoint,代表所有分片都已写入这个序号的位置。
local checkpoint代表当前分片已写入成功的最新位置,恢复时通过对比两个序列号,计算出缺失的数据范围,然后通过translog重放这部分数据,同时translog会为此保留更长的时间。
因 此 , 有两个机会可以跳过副分片恢复的phase1: 基 于SequenceNumber,从主分片节点的translog恢复数据;主副两分片有相同的syncid且doc数相同,可以跳过phase1。
集群启动日志
日志是分布式系统中排查问题的重要手段,虽然 ES 提供了很多便于排查问题的接口,但重要日志仍然是不可或缺的。默认情况下,ES输出的INFO级别日志较少,许多重要模块的关键环节是DEBUG或TRACE 级别的。
小结
当一个索引的主分片分配成功后,到此分片的写操作就是允许的。
当一个索引所有的主分片都分配成功后,该索引变为Yellow。
当全部索引的主分片都分配成功后,整个集群变为Yellow。
当一个索引全部分片分配成功后,该索引变为 Green。
当全部索引的索引分片分配成功后,整个集群变为Green。
索引数据恢复是最漫长的过程。当shard总量达到十万级的时候,6.x之前的版本集群从Red变为Green的时间可能需要小时级。ES 6.x中的副本允许从本地translog恢复是一次重大的改进,避免了从主分片所在节点拉取全量数据,为恢复过程节约了大量时间。